Artificial neural networks are powerful computational models based off of biological neural networks. The neural network has an input layer, hidden layer, and output layer, all connected by weights. The inputs, with interconnection weights, are fed into the hidden layer. Within the hidden layer, they get summed and processed by a nonlinear function. The outputs from the hidden layer, along with different interconnection weights, are processed one last time in the output layer to produce the neural network output. It learns its weights through backpropagation and is able to model any continuous non-linear function.
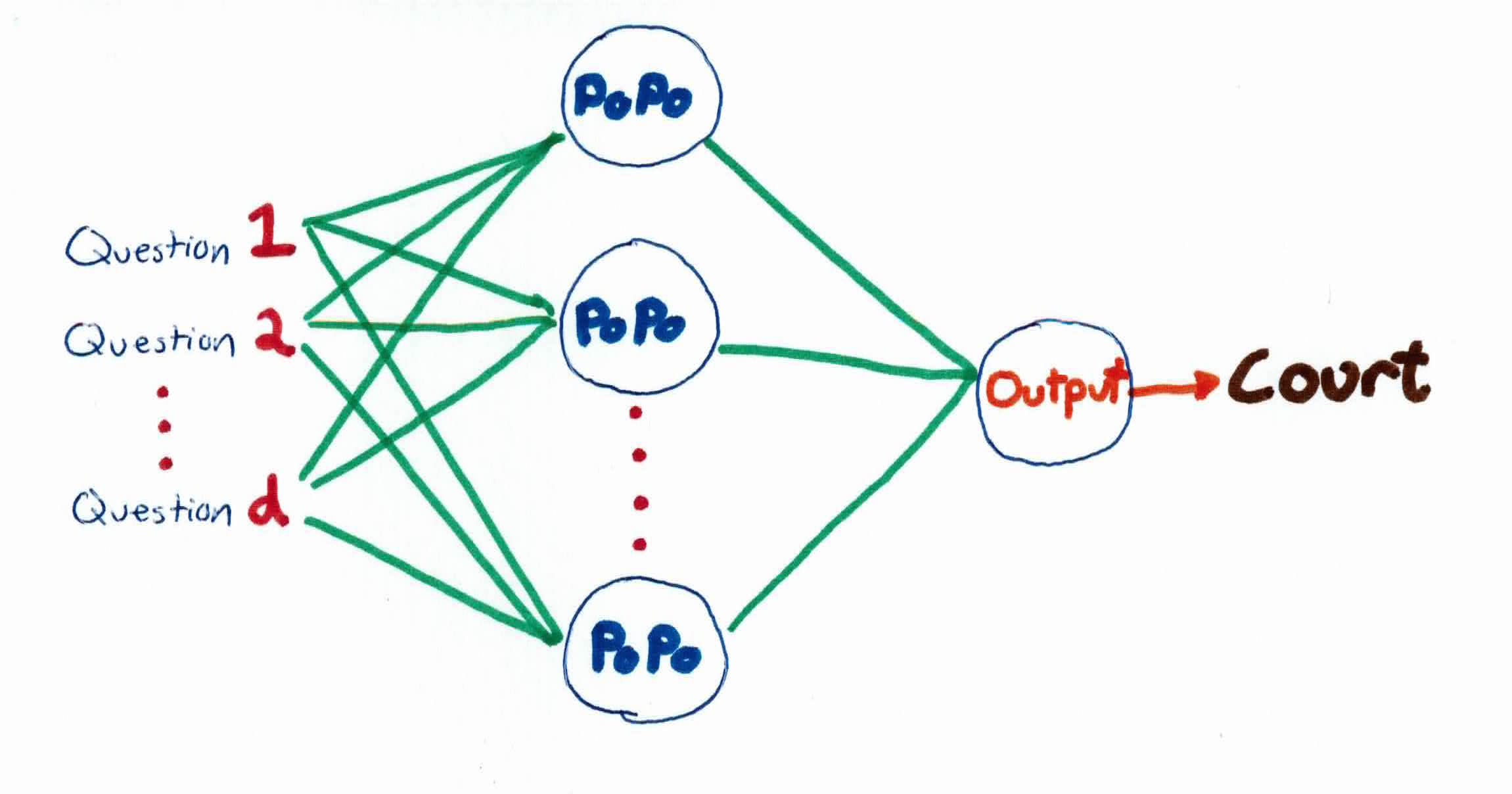
Recall that in the perceptron story, the 45th couldn't get the job done. You're the 46th. You have the same goal of making America safe by stopping criminals, but only criminals, not necessarily undocumented immigrants. You realize that a straight, border wall can't do that.
Instead of ICE agents, we use multiple police stations around the country (hidden neurons). Police officers go around asking for peoples information and are deemed as criminals if they pass a certain threshold.
We are more sophisticated than the 45th (perceptron), so we don't just build one straight wall to separate criminals from non-criminals. Each police station combines information with other police stations, consequently allowing us to capture any criminal, creating arbitrary boundaries.
Once a criminal has been determined by the police, they are then tried in court. If the person is found not-guilty (misclassified), the policemen then send out the information about their mistake to all the other police stations. The police then adjust the emphasis on the type of questions they ask and answers they receive, hoping to be able to be more accurate in who they think are criminals. This, in essence, is how backpropagation works to find weights for the neural network.
Recall that the perceptron uses a step function and predicts with:
$$f(x) = sign(w^Tx) = sign(\sum_{j=0}^d w_j x_{ij})$$
where $x \in \mathbb{R}^d$ with $d$ features and $x_{i,0}$ is set to 1 because $w_0$ is our bias.
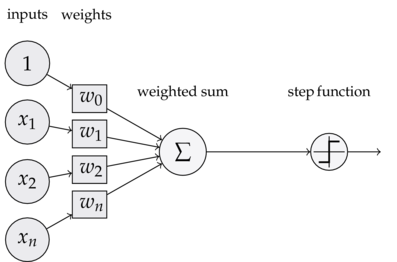
It's an iterative method that starts with a random hyperplane and adjusts it using your training data. It can represent Boolean functions such as AND, OR, NOT, but not the XOR function. It produces a linear separator in the input space which works perfectly if the data is linearly separable. If not, then it will unfortunately not converge.
That's where Neural Networks come in. Neural Networks use the ability of the perceptrons to represent elementary functions and combine them in a network of layers. The structure of a neural network consists of a series of layers, each composed of one or more neurons/perceptrons. Each neuron produces an output, or activation, based on the output of the previous layer and a set of weights.
However, a cascade of linear functions is still linear. Yet, we want networks that represent highly non-linear functions. Also, perceptron uses a step function, which is undifferentiable and not suitable for gradient descent in case data is not linearly separable.
One possibility is to use the sigmoid function that we saw in logistic regression:
$$g(z) = \frac{e^z}{1+e^z} = \frac{1}{1+e^{-z}}$$
$$g(z) \rightarrow 1 \ when \ z \rightarrow + \infty$$
$$ g(z) \rightarrow 0 \ when \ z \rightarrow - \infty $$
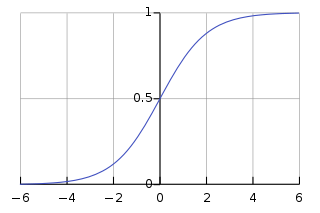
So, our new network will consist of pieces like this, instead of the perceptron with the step function:
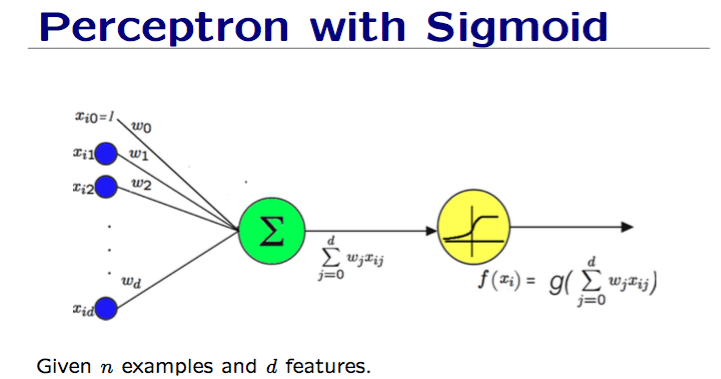
Remember, we're combining multiple perceptrons (with sigmoid, not step function) together to create a neural network.
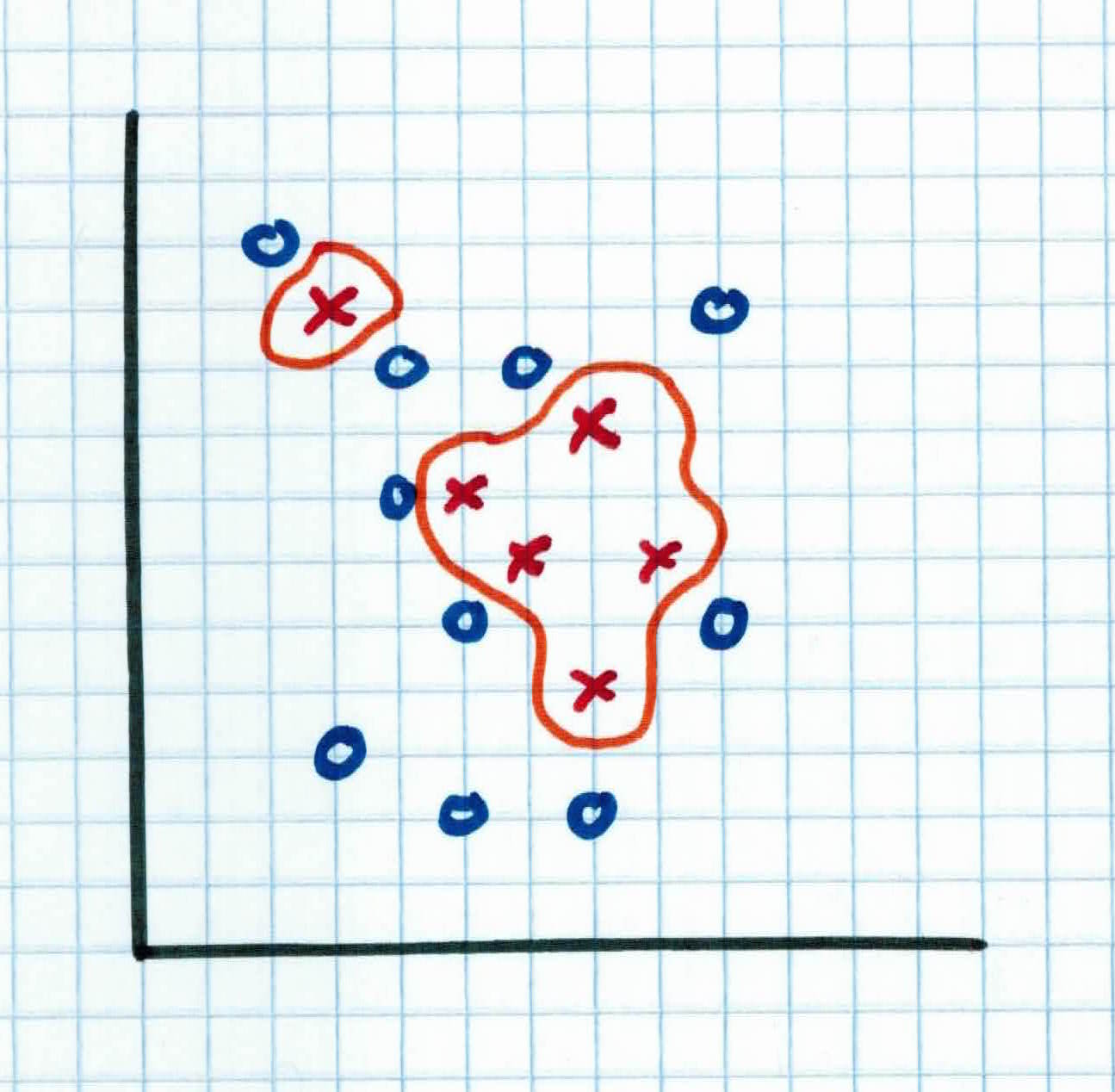
Let's illustrate the differences by trying to compute the XOR function. Recall that the XOR function is as such:
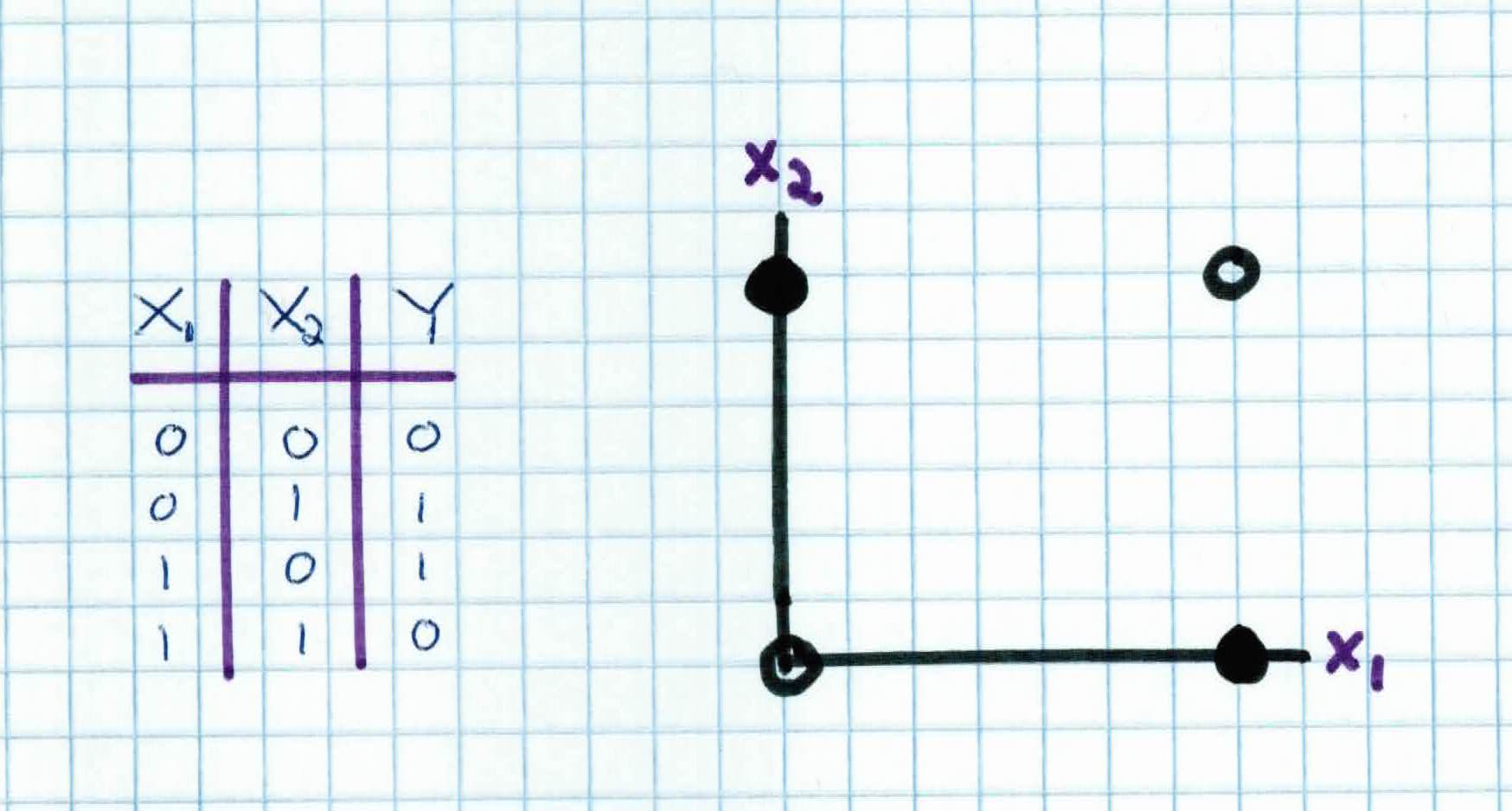
Notice that the perceptron cannot find the separating hyperplane to classify the XOR function. To build a classifier that will find a way to split the points, we utilize the power of neural networks and combine different functions together.
For instance, we first compute the OR function:
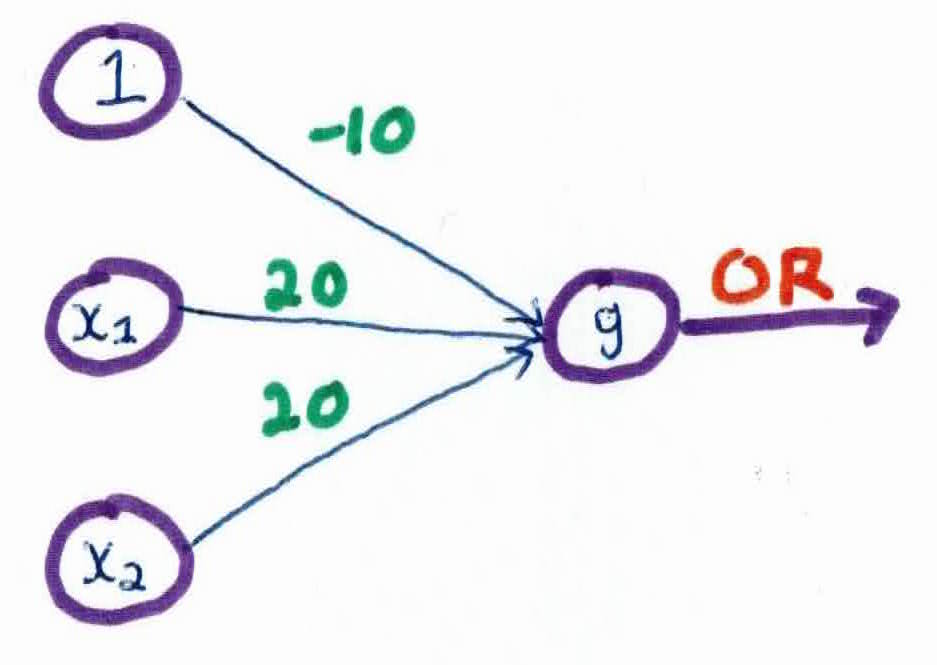
This network produces the OR function, as you can see by the table below:
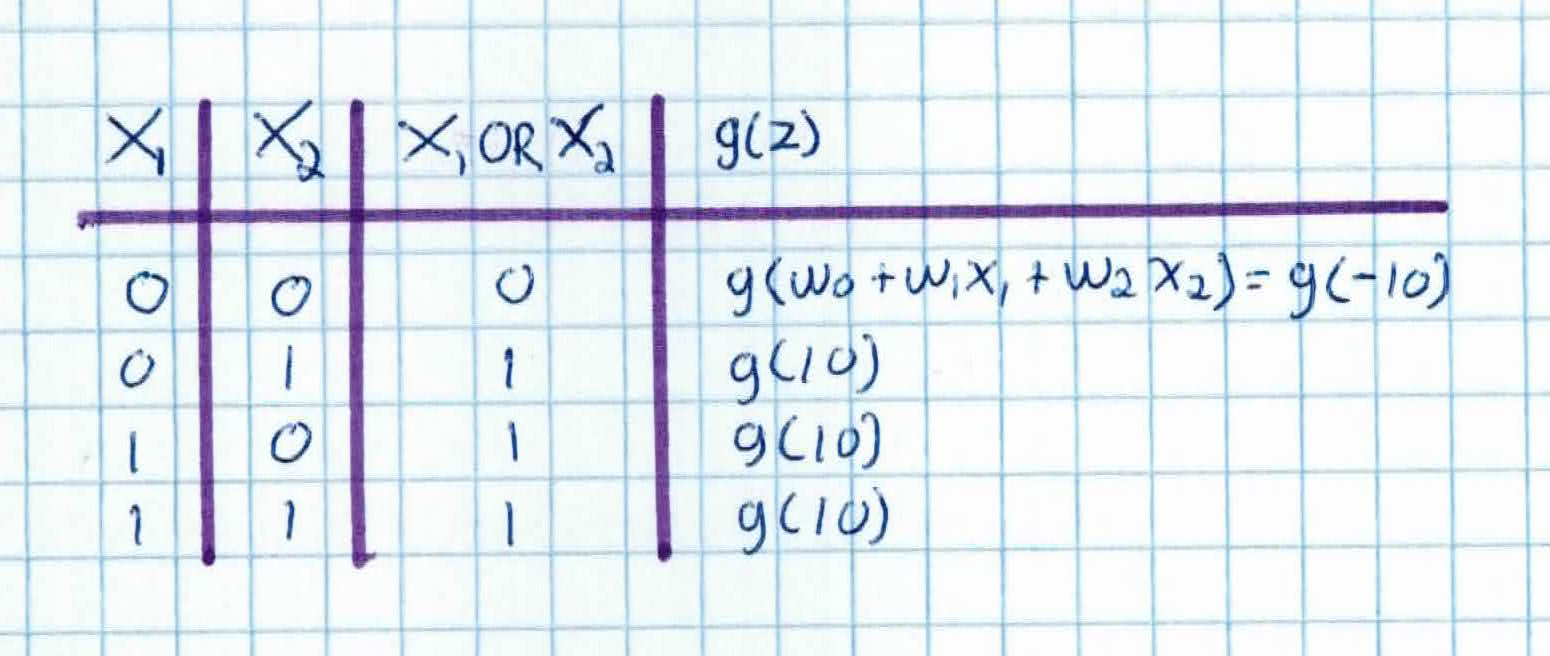
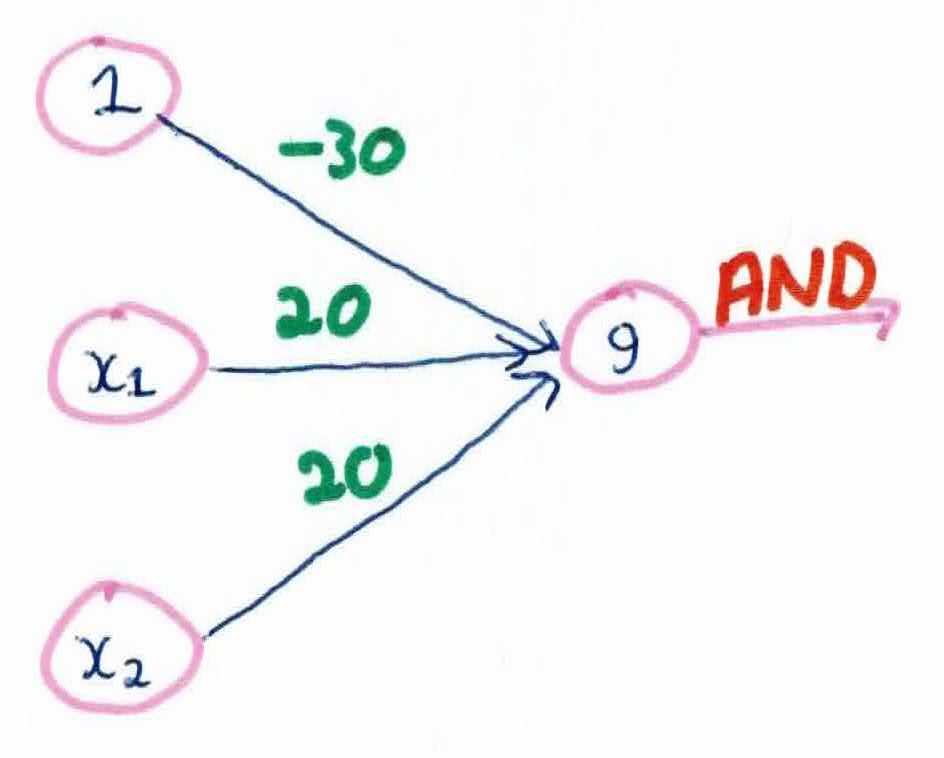
We then compute the AND function:
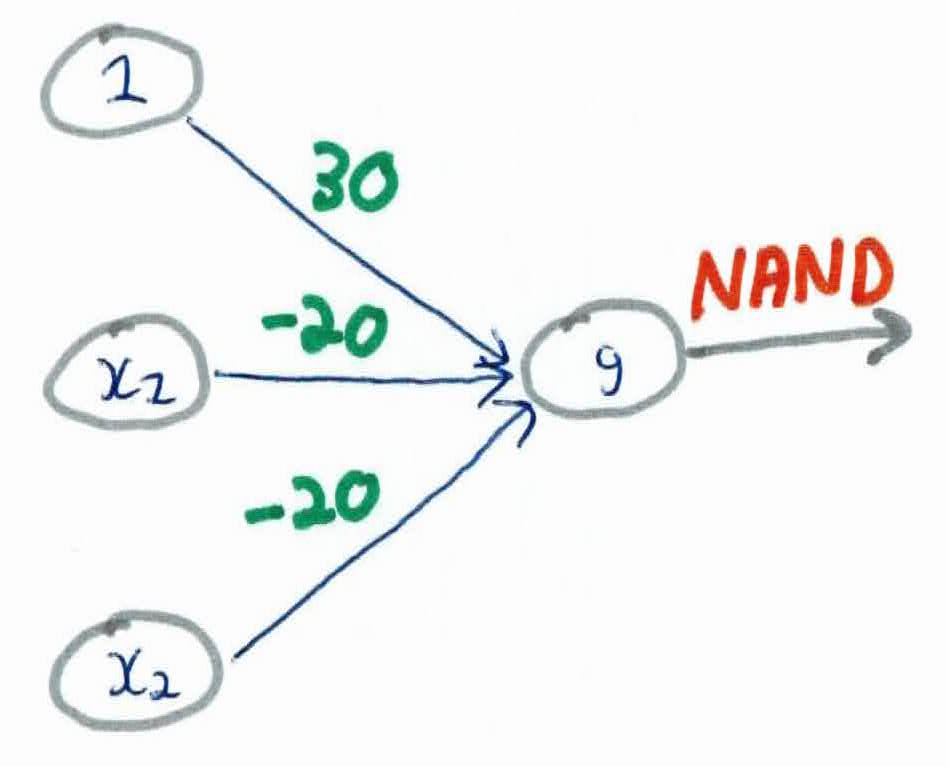
Then the NAND function:
Finally, after combining these three functions into one full neural network, we get:
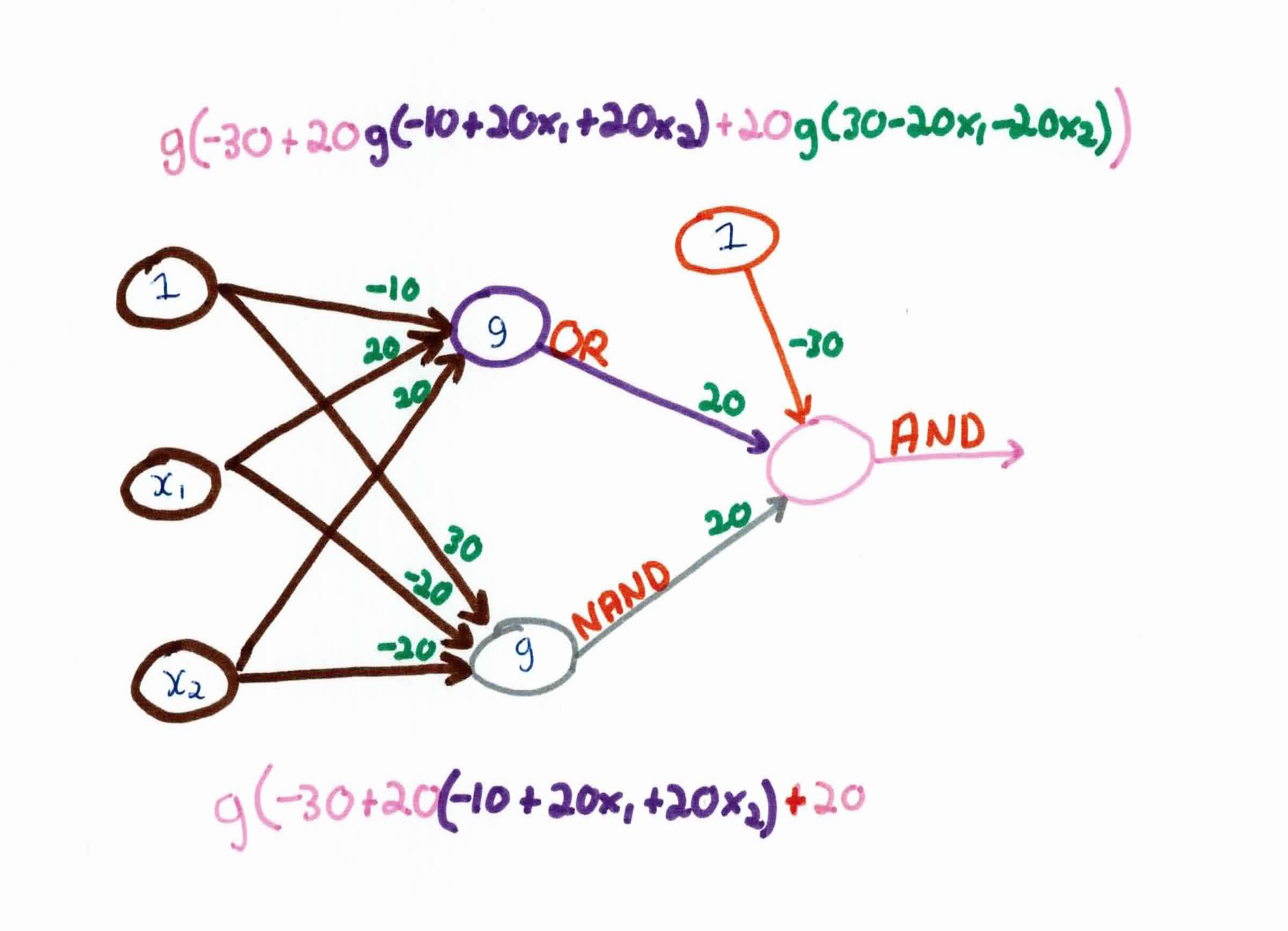
As you can see, by using a neural network, we can combine different functions together with different weights to approximate the XOR function. Our model will now be able to classify data based on the XOR function, something that the perceptron couldn't do.
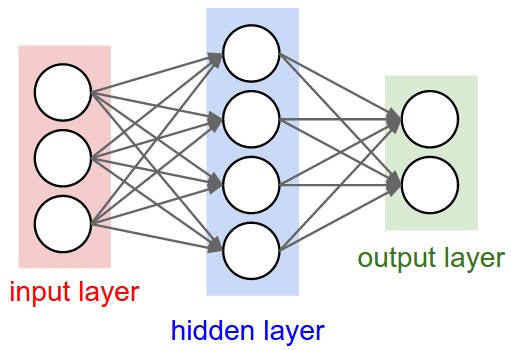
When using a neural network to approximate a function, the data is forwarded through the network layer-by-layer until it reaches the final layer. Each neuron in the hidden layer transforms the values from the previous layer with a weighted linear summation, followed by a non-linear activation function. The output layer receives the values from the last hidden layer and transforms them into output values. But, how do we go about constructing our neural network for different problems? All neural networks have 3 layers: input, hidden, and output. The number of hidden layers can add or remove functionality. For example:
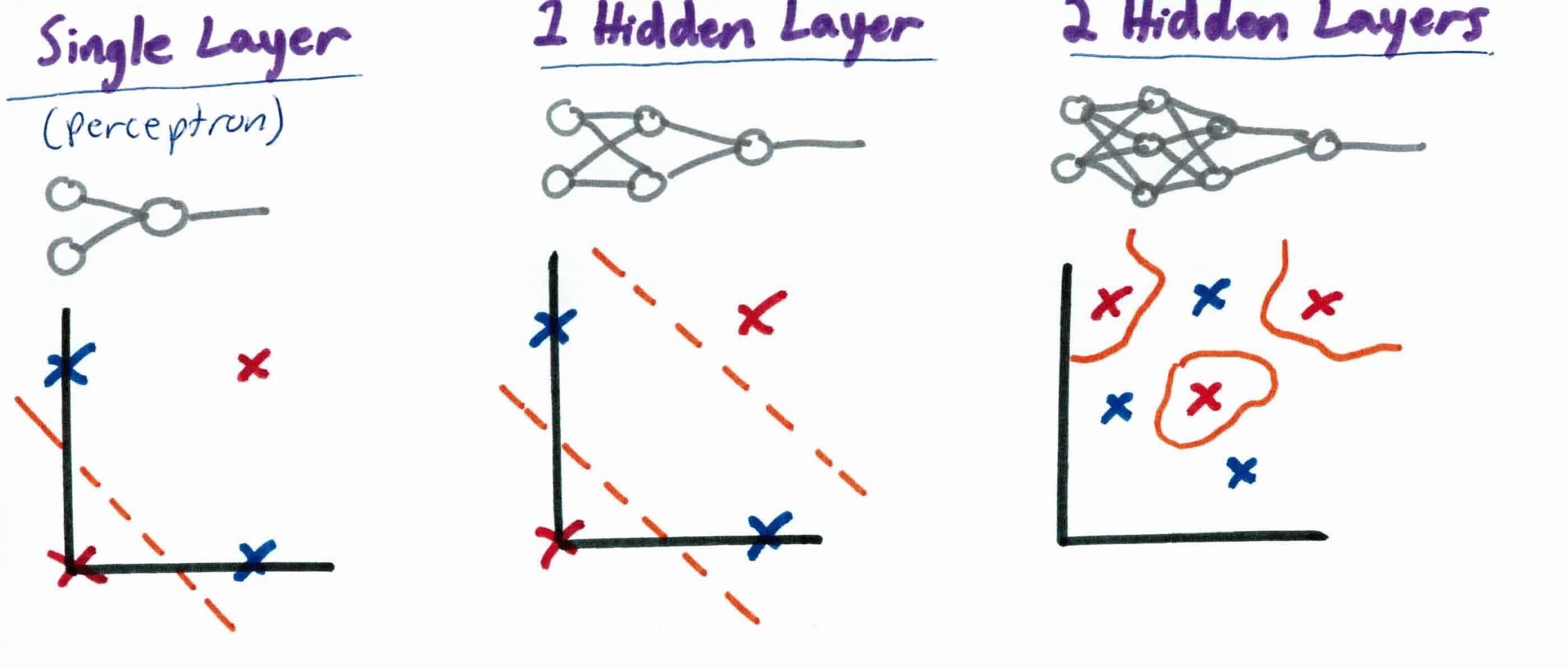
As you can see, a hidden layer adds more functionality to they system. A single perceptron gets one linear function, 1 hidden layer is non linear and 2 or more can find arbitrary boundaries. 2 or more hidden layers is known as deep learning and will be discussed more in later guides.
All of this probably seems kind of magical, but it actually works. The key is finding the right set of weights for all of the connections to make the right decisions.
But how do we find the proper weights? We use backpropagation. Before moving on to backpropagation, make sure you understand partial derivatives/gradients.
In a neural network, we feedfoward the information from one layer to another layer, to produce an output. In backpropagation, we pass the errors backwards so the network can learn by adjusting the weights of the network. Backpropagation stands for backward propagation of errors.
When we’re training the network, it’s often convenient to have some metric of how good or bad we’re doing; we call this metric the cost function, which is given by:
$$J(w) = \frac{1}{2}\sum_k (y_k - o_k)^2$$
Our cost function is calculating the difference between the correct value and our predicted value (we square it and divide by 2 for mathematical convenience). We want this to be as low as possible.
Just like in linear regression and logistic regression, your goal in backpropagation is to find the weights that will minimize this cost function $J$. This is done by using gradient descent to minimize the squared error between the network output value $o$ and each node $k$ in the network. Think of it as you trying to find the rate of change/gradient at each neuron.
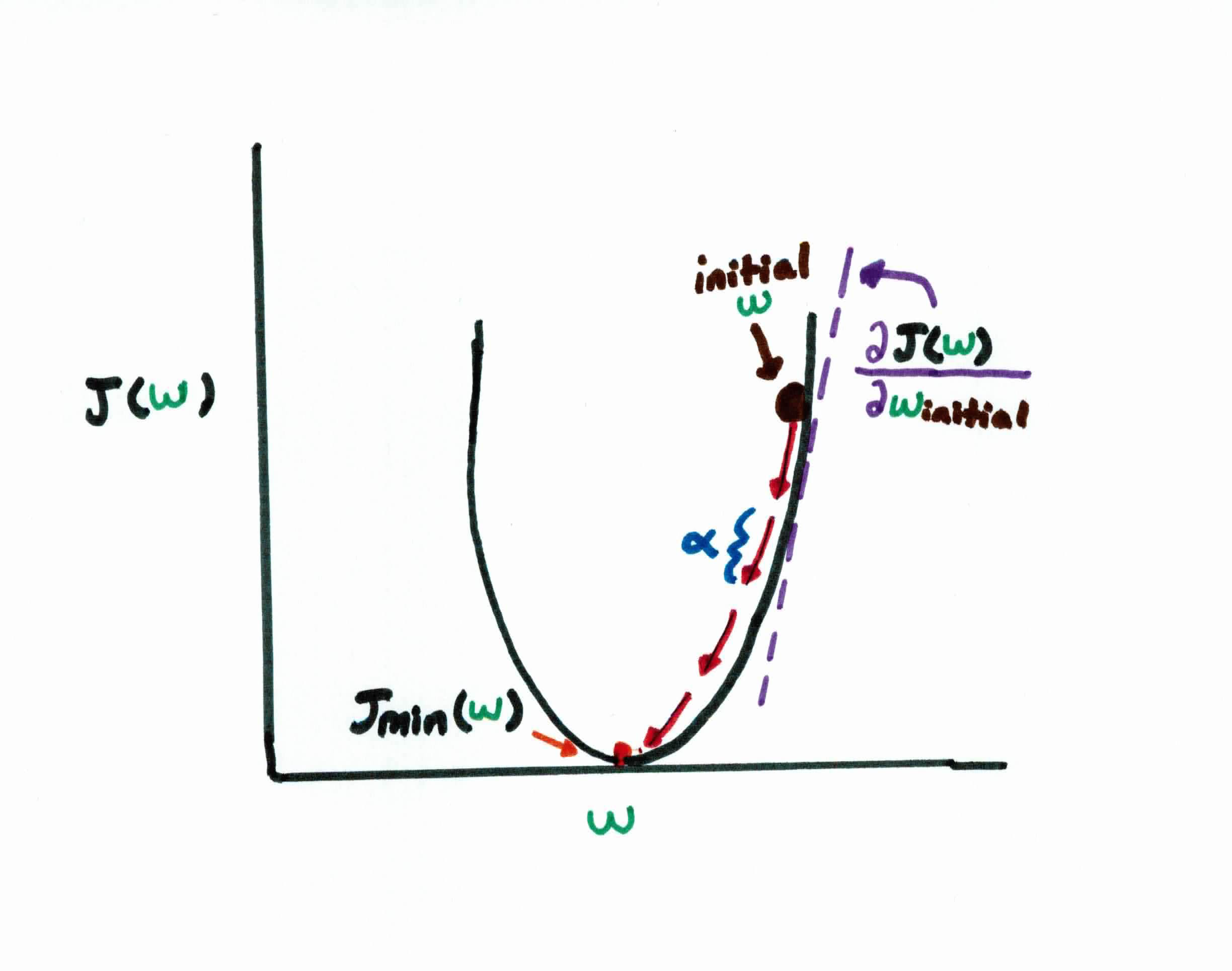
Recall that in gradient descent, we start off by initializing our weights randomly, which puts us at the black dot on the diagram above. Taking the gradient of $J(w)$, with respect to $w$, we see the slope at this point is a pretty big positive number. We want to move closer to the bottom center, because we want to find the minimum cost, so naturally, we should take a pretty big step $\alpha$ in the opposite direction of the slope. So, basically we are constantly updating our weights:
$$w_{ij} = w_{ij} -\alpha \frac{\partial J(w)}{\partial w_{ij}}$$
until we reach the minimum.
Remember that the step size $\alpha$ can make or break your program. If the step size is too small, it will take forever for your program to converge. If it is too big, it might overshoot your global minimum and never converge. If we repeat the process enough, we soon find ourselves nearly at the bottom of our curve and much closer to the optimal weight configuration for our network.
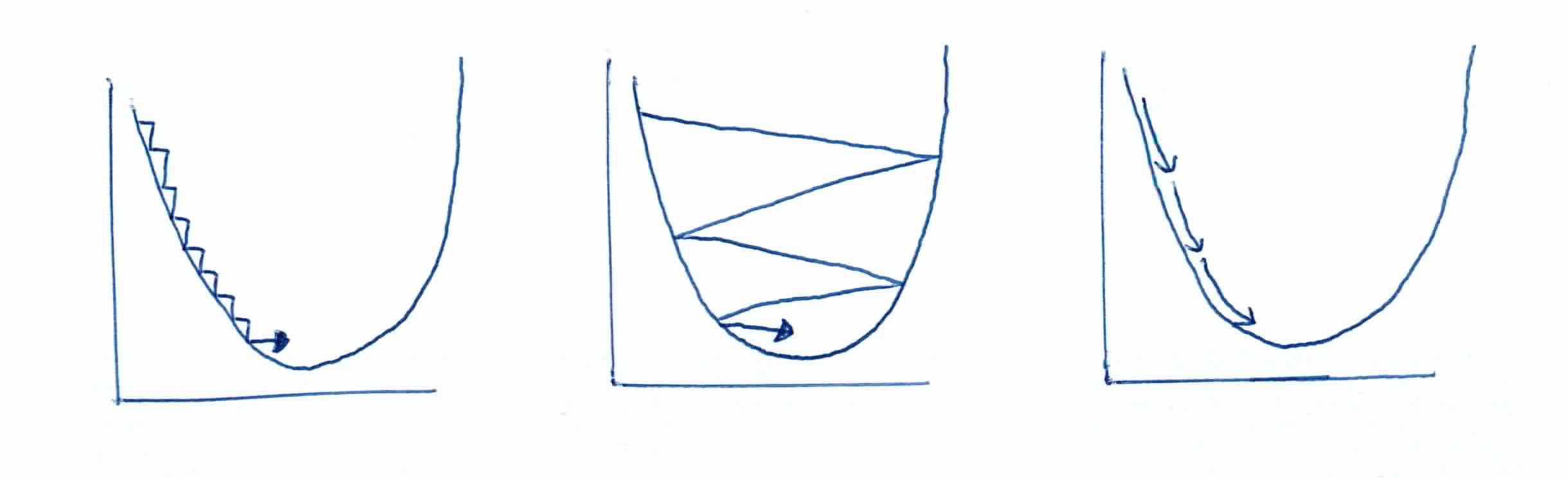
For a simple two-layer network (without a hidden layer), the error surface is bowl shaped and using gradient-descent to minimize error is not a problem as the network will always find the bottom of the bowl called the global minima. However, when an extra hidden layer is added to solve more complex problems, the possibility arises for complex error surfaces which contain many minima, and it is possible that gradient descent won't find the global minima and end up in a local minima which represents suboptimal solutions.
As a general rule of thumb, the more hidden units you have in a network, the less likely you are to encounter a local minimum during training. Although additional hidden units increase the complexity of the error surface, the extra dimensionality also increases the number of possible escape routes.
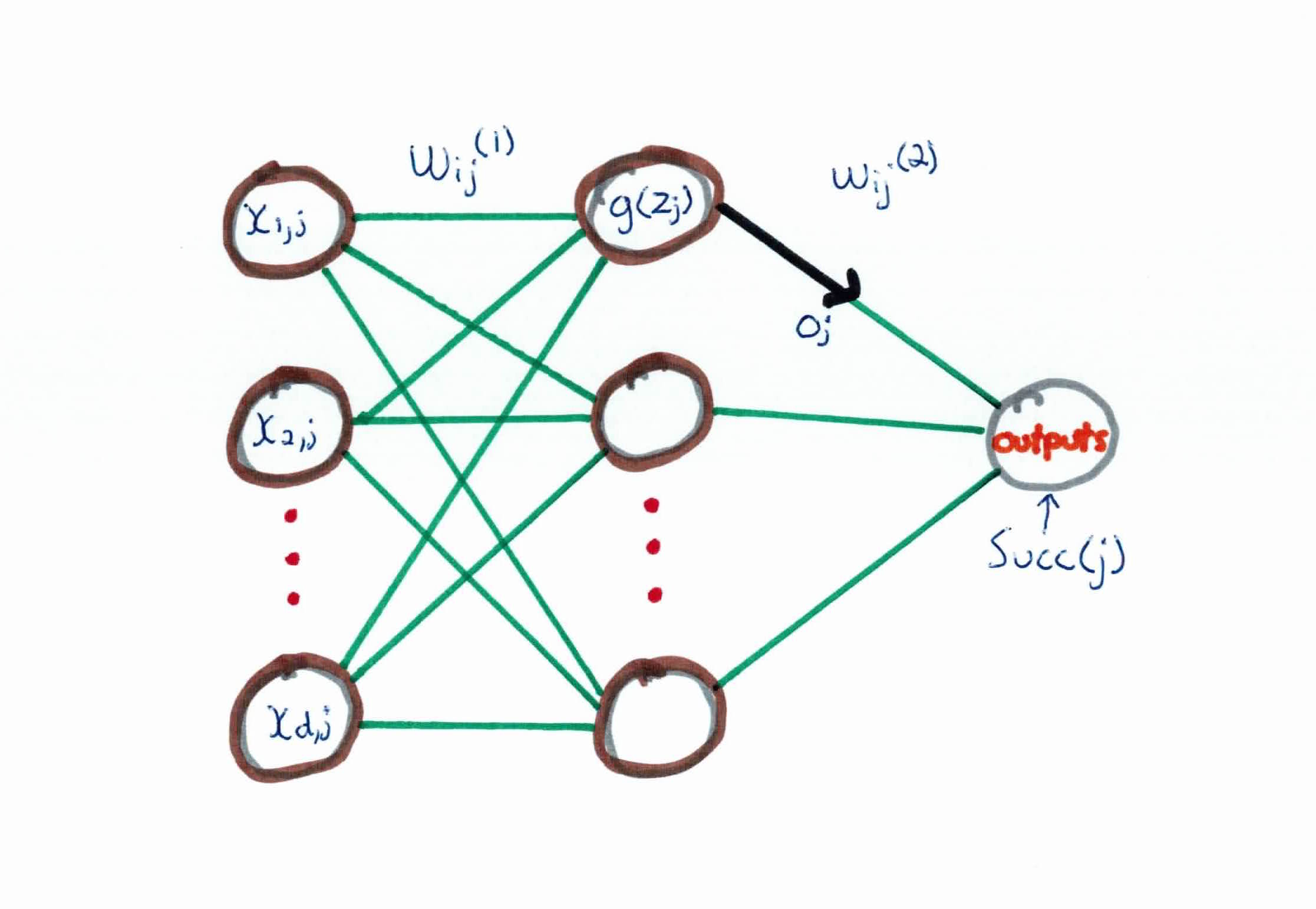
Before going over the math, lets clear up some notation:
Consider $k$ outputs. For an example $e$, the error on training example $e$, summed over all output neurons in the network is:
$$J(w) = \frac{1}{2}\sum_k (y_k - o_k)^2$$
Rememeber, gradient descent iterates through all the training examples one at a time, descending the gradient of the error w.r.t. this example is:
$$\bigtriangleup w_{ij} = -\alpha \frac{\partial J(w)}{\partial w_{ij}}$$
where $\alpha$ is our learning rate, i.e. how big of a step down/up the gradient we take.
Calculating the partial differential equation, we get:
$$\frac{\partial J}{\partial w_{ij}}=\frac{\partial J}{\partial z_j} \frac{\partial z_j}{\partial w_{ij}} = \frac{\partial J}{\partial z_j} x_{ij} $$
So, we have $\bigtriangleup w_{ij} = -\alpha \frac{\partial J}{\partial z_j} x_{ij}$
Make sure you understand how we got here using the chain rule.
For $\frac{\partial J}{\partial z_j}$ we need to calculate it for 2 different cases:
In case 1 where we have an output neuron, we have:
$$\frac{\partial J}{\partial z_j} = \frac{\partial J}{\partial o_j} \frac{\partial o_j}{\partial z_j}$$
$$\frac{\partial J}{\partial o_j} = \frac{\partial}{\partial o_j} \frac{1}{2} \sum_k (y_k - o_k)^2$$
$$= \frac{\partial}{\partial o_j} \frac{1}{2} (y_j - o_j)^2 $$
$$= \frac{1}{2} 2 (y_j - o_j) \frac{\partial (y_j - o_j)}{\partial o_j} $$
$$ = -(y_j -o_j)$$
Recall that $o_j = g(zj)$ and computing $\frac{\partial o_j}{\partial z_j}$ we have:
$$\frac{\partial o_j}{\partial z_j} = \frac{\partial g(z_j)}{\partial z_j}$$
$$= o_j (1-o_j) $$
Plugging both back into $\frac{\partial J}{\partial z_j} = \frac{\partial J}{\partial o_j} \frac{\partial o_j}{\partial z_j}$ we have:
$$\frac{\partial J}{\partial z_j} = -(y_j - o_j)o_j(1-o_j) $$
$$\bigtriangleup w_{ij} = \alpha (y_j -o_j)o_j(1-o_j)x_{ij} $$
To clean it up, we will set the equations as such:
$$\delta_j =- \frac{\partial J}{\partial z_j}$$
$$\bigtriangleup w_{ij} = \alpha \delta_j x_{ij} $$
In case 2 where we have a hidden neuron, we have:
$$\frac{\partial J}{\partial z_j} = \sum_{k \in succ { j}} \frac{\partial J}{\partial z_k} \frac{\partial z_k}{\partial z_j} = \sum_{k \in succ { j } } - \delta_k \frac{\partial z_k}{\partial z_j}$$
$$= \sum_{k \in succ { j } } -\delta_k \frac{\partial z_k}{\partial o_j} \frac{\partial o_j}{\partial z_j}$$
$$= \sum_{k \in succ { j } } -\delta_k w_{jk} \frac{\partial o_j}{\partial z_j}$$
$$= \sum_{k \in succ { j } } -\delta_k w_{jk} o_j (1-o_j) $$
$$\delta_j = -\frac{\partial J}{\partial z_j} = o_j (1-o_j)\sum_{k \in succ { j } } \delta_k w_{jk} $$
We then plug either $\delta_k$ or $\delta_h$ into the weight update rule:
$$w_{ij} \leftarrow w_{ij} + \alpha \delta_j x_{ij}$$
and we keep iterating and repeating until convergence.
Make sure you're taking your time to carefully understand all the math by walking through it, line by line. Try to derive it yourself and check this guide when you get stuck.
Given a training set ${(x_1, y_1), \ldots (x_n, y_n)}$, learning rate $\alpha$ (e.g., $\alpha = 0.1$), and ($N_{input}$, $N_{hidden}$, $N_{output}$) where $N_{input}$ = # of inputs, etc., the Backpropagation algorithm to find NN weights works like this:
For our example, we are going to learn the XOR function. The basic structure our our neural network will have two inputs. Our training data is:
$$x_1 = (0,0), \ y = 0$$
$$x_2 = (1,0), \ y = 1$$
$$x_3 = (0,1), \ y = 1$$
$$x_4 = (1,1), \ y = 0$$
We have two input layers, two hidden layers, and one output (0 or 1). For our example, we will run $x_3$ first, which should output a 1 if we are trying to learn the XOR function. We set our learning rate $\alpha = 0.5$. Number of iterations can be set till convergence or a constant number. In this example we will run one iteration on one example. It looks as follows:
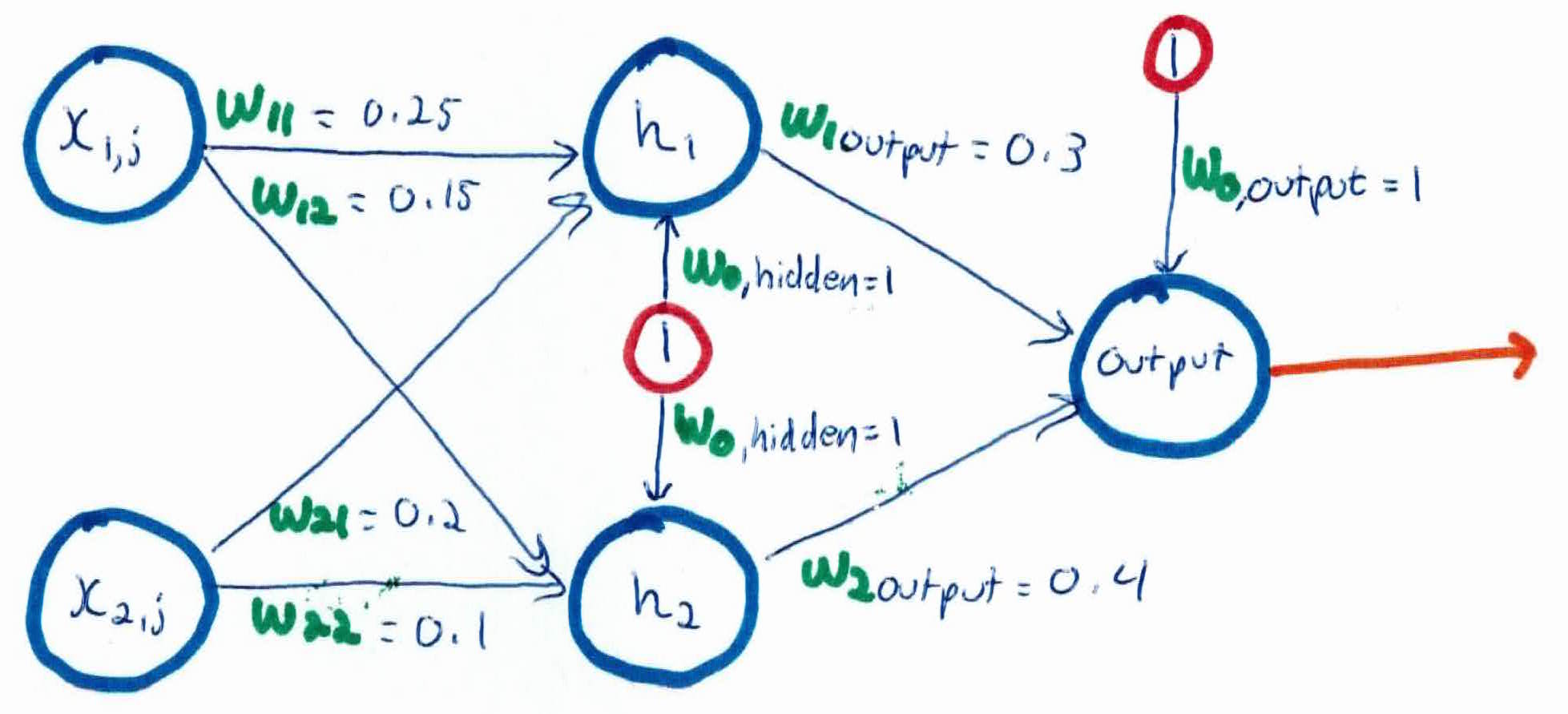
Our first step is the feedforward step, where we pass the inputs up the network.
$$h_1 = sigmoid(x_{1,1}w_{1,1} + x_{2,1} w_{2,1} + w_{0,hidden})$$
$$= sigmoid(0.25 + 0 + 1) = \frac{1}{1+e^{-1.25}} = \frac{1}{1.287} = .777$$
$$h_2 = sigmoid(x_{1,2}w_{1,2} + x_{2,2}w_{2,2} + w_{0, hidden})$$
$$= sigmoid(0.15 + 0 + 1) = \frac{1}{1+e^{-1.15}} = \frac{1}{1.316} = 0.759$$
The output from the hidden neurons $h_1$ and $h_2$ are now used as inputs to the output layer:
$$output = sigmoid(h_1w_{1,output} + h_2w_{2, output} + w_{0, output})$$
$$=sigmoid((0.777)(0.3)+(0.759)(0.4) + 1) = sigmoid(1.54)$$
$$= \frac{1}{1+e^{-1.54}}=\frac{1}{1.214}=0.824$$
If we calculate the error on our current predictions using our cost function, or squared error function, $J = \sum_{outputs} \frac{1}{2}(target-output)^2$ (we use $\frac{1}{2}$ and square it to make the function more mathematically convenient when we take the derivative) we get
$$J = \frac{1}{2}(1-0.824)^2 = \frac{1}{2}(0.176)^2 = 0.0155$$
Our goal is to get this total error as low as possible. So, if we run till convergence, that means to run until the error is as low $\epsilon$, a value that we preset.
To actually learn from the data and alter our weights, we run backpropagation which is now sends our information down the network, altering the weights based on our error.
Recall, to do this, for each output $k$, we must calculate our $\delta$'s using the formula
$$\delta_k = o_k (1-o_k)(y_k - o_k)$$
$$\delta_{output} = (0.824)(1-0.824)(1-0.824)$$
$$=(0.824)(0.176)(0.176) = 0.0255$$
We then use these $\delta$'s to update our weights, using the formula
$$w_{ij} \leftarrow w_{ij} + \alpha \delta_j x_{ij}$$
$$w_{1,output} = 0.3 + (0.5)(0.0255)(0.777) = 0.3099$$
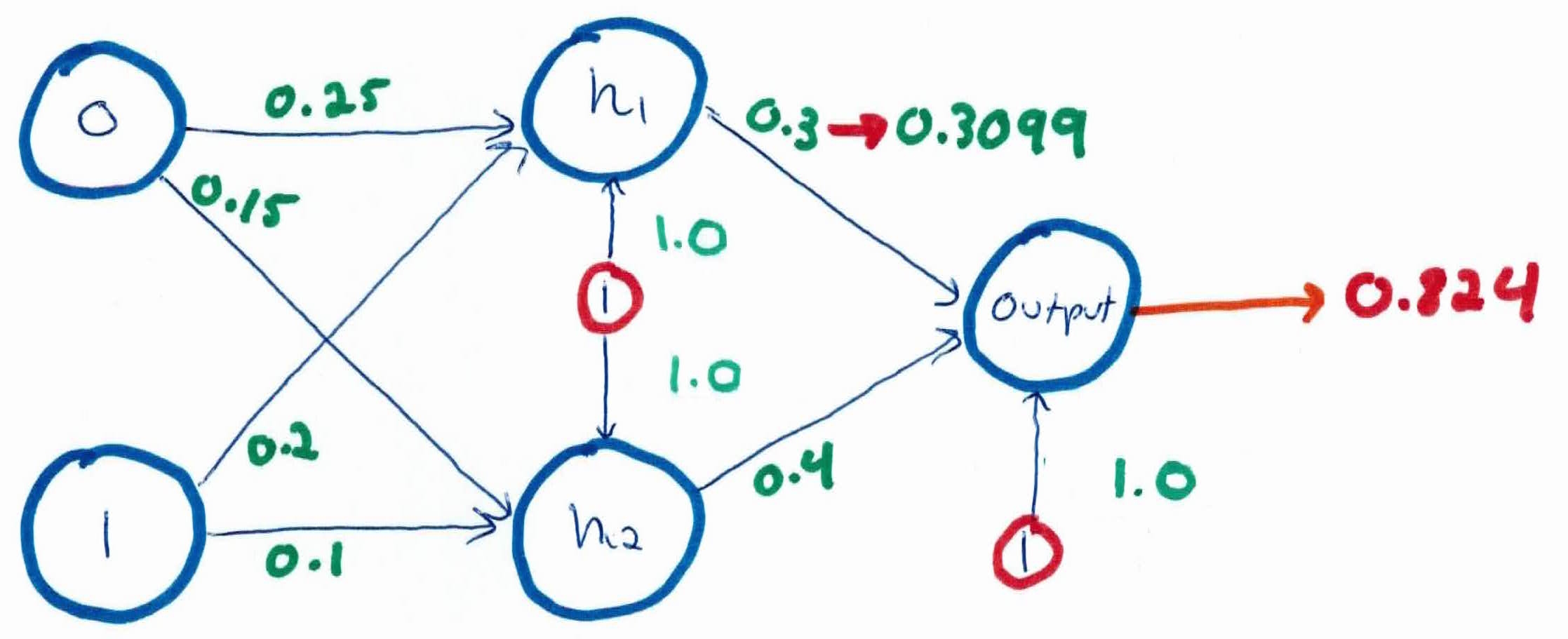
$$w_{2,output} = 0.4 + (0.5)(0.0255)(0.759) = 0.4097$$
$$w_{0,output} = 1.0 + (0.5)(0.0255)(1) = 1.01275$$
As you can see, the weights connecting to the $ouput$ are increasing, since we want the output to be bigger and closer to 1.
We perform the actual updates for the weights in this neural network after we have the new weights leading into the hidden layer i.e. we use the original weights, not the updated weights when we continue the original backpropagation algorithm below.
For the weights leading into the hidden layer, he have to compute the $\delta$'s using the formula
$$\delta_h = o_h (1-o_h) \sum_{k \in Succ (h)} w_{hk}\delta_k$$
$$\delta_{h1} =(0.777)(1-0.777)((0.3)(0.255)) = 0.00132$$
$$\delta_{h2} =(0.759)(1-0.759)((0.4)(0.255)) = 0.00187$$
Now when we update using the same formula, $w_{ij} \leftarrow w_{ij} + \alpha \delta_j x_{ij}$, we get:
$$w_{0,h_1} = 1.0 + (0.5)(0.00132)(1) = 1.001$$
$$w_{0, h_2} = 1.0 + (0.5)(0.00187)(1) = 1.001$$
$$w_{1,1} = 0.25 + (0.5)(0.00132)(1) = 0.251$$
$$w_{1,2} = 0.15 + (0.5)(0.00187)(1) = 0.151$$
$$w_{2,1} = 0.2 + (0.5)(0.00132)(0) = 0.20$$
$$w_{2,2} = 0.1 + (0.5)(0.00187)(0) = 0.10$$
Our updated neural network now looks like:
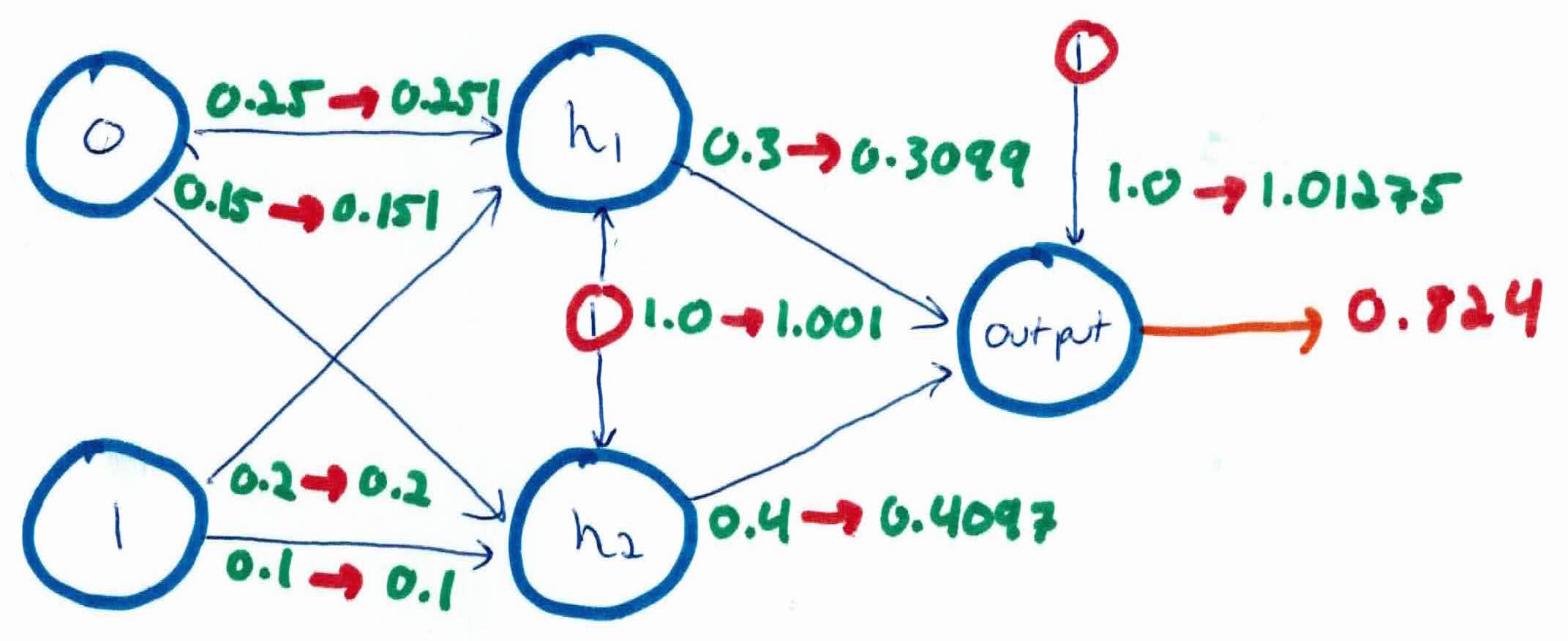
You now continue this process on the rest of the inputs/examples, constantly updating the weights, until convergence. After a number of iterations, the weights will be optimal and your neural network will have learned the XOR function.
Artificial neural networks, like real brains, are computational models formed from connected “neurons”, all capable of carrying out a data-related task. They are based on a large collection of connected simple units called artificial neurons. Each neuron is capable of passing on the results of its work to a neighboring neuron, which can then process it further. Because the network is capable of changing and adapting based on the data that passes through it, so as to more efficiently deal with the next bit of data it comes across, it can be thought of as “learning”, in much the same way as our brains do. Connections betweens neurons carry a unidirectional signal with an activating strength that is proportional to the strength of the connection between this neurons. If the combined incoming signals are strong enough, the postsynaptic neuron becomes activated and a signal propagated to downstream neurons connected to it.
Neural networks use the weighs to learn a function. Neural networks use backpropagation to modify weight connections and to train the network using known correct outputs.
Other observations: