Before jumping into the machine learning algorithms, I'll first describe some of the nomenclature.
Each data point is called a training example, and is usually denoted $x_i$ with $i$ being the $i$-th training example. Each training example consists of $d$ features and can be denoted $x_{i,d}$ which is the $i$-th training example's $d$-th feature.
Therefore, the 7th feature in the 3rd training example would be denoted like $x_{3,7} $.
Using our previous example, imagine from 2008-2016 we collected data from 10,000 customers. For each customer, we collected their net income, education, health records, search history, and whether they have kids or not. Therefore, we would have 10,000 training examples and 5 features. The education level of the 4880th customer would be denoted as $x_{4880, 2}$
Whether the 10,000 people bought our product or not are known as the labels. Denoted as $y_i$ for the $i$-th label (person). So, $y_3 = 1$ would mean that the 3rd customer did indeed buy our product, while $y_{1024} = 0$ means the 1024th customer didn't buy our product. Whether they bought the product or not is the label because that is what we are trying to predict/classify. Label is synonymous with answer.
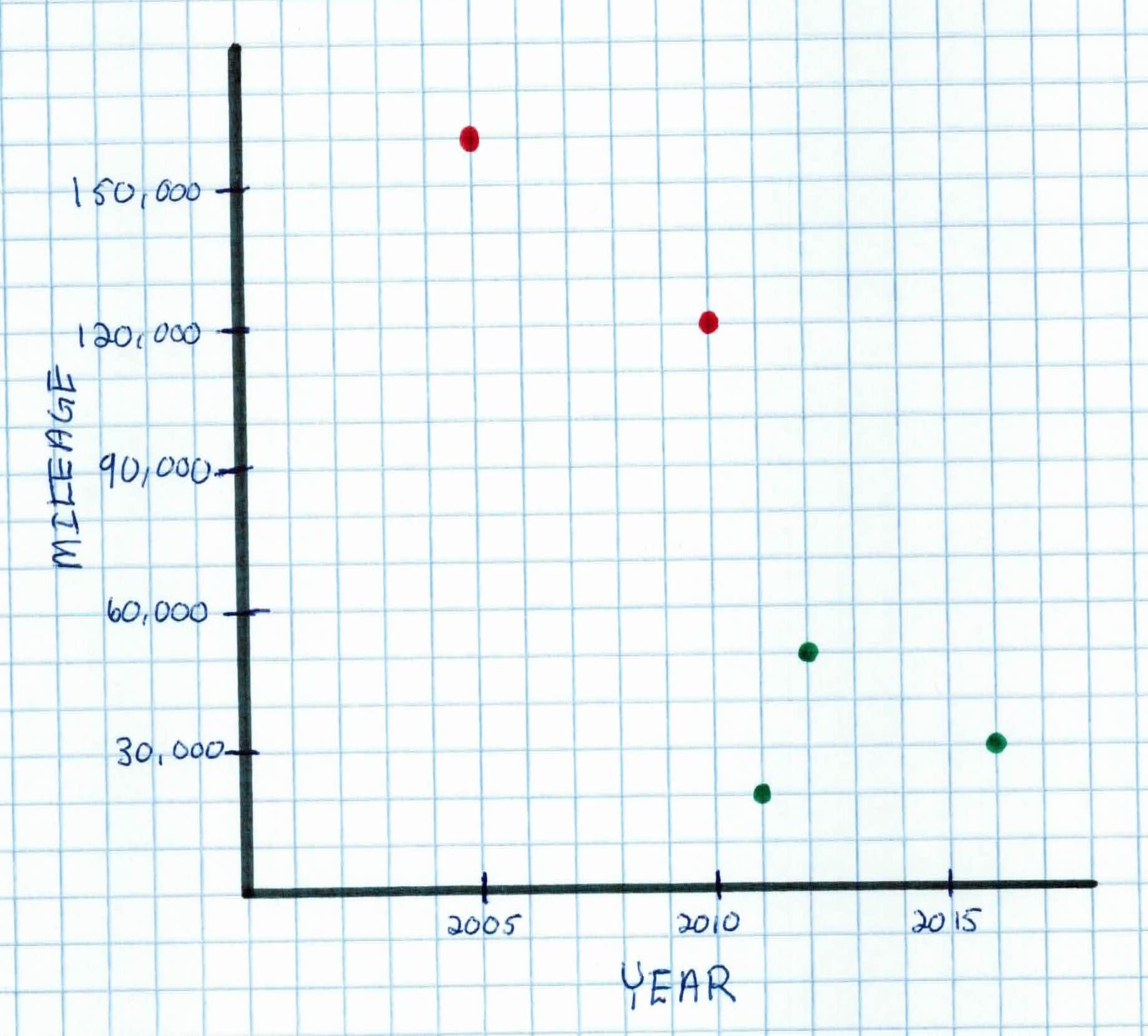
We model this data in the feature space. This means that we can plot all of our data with the features being the dimensions. For example, assume that we had 3 cars (our training data). Their features are mileage and year. Their labels are new car or old car. Since we have 2 features, we have $x_i \in \mathbb{R}^2$, which means that all $x_i$ will be in a 2 dimensional space.
Our data has the form $x_i = (x_{i, 1}, x_{i, 2})$ and is given as: $$x_1 = (160000, 2005), \ y_1 = 0$$ $$x_2 = (120000, 2010), \ y_2 = 0$$ $$x_3 = (30000, 2016), \ y_1 = 1$$ $$x_4 = (20000, 2011), \ y_1 = 1$$ $$x_5 = (50000, 2012), \ y_1 = 1$$ with the first feature $x_{i,1}$ being mileage, $x_{i,2}$ being year, and the label being $y_i = 0$ if the car is old (and 1 if new). When we plot our data in 2-dimensional space, it looks like so:
The goal of most machine learning algorithms is to find a decision boundary that will separate the data. This is done so that when we have new a data point $x_{new}$, we simply see what side of the line that it's placed on, and predict it's label accordingly.
When there is a label present in our training data, we can use supervised learning. That's when we send the training data along with the label into the machine learning algorithm. The algorithm then finds the patterns that result in the label. If we are just given the training data with no label, then we use unsupervised learning. Most unsupervised algorithms are clustering algorithms. They simply group common examples together based on their features. The purpose is to help us gain insight on the data and see any similarities, if any.
In probabilistic terms, unsupervised learning is about learning something about a probability distribution $p(x)$ based on samples from $x$. While supervised learning is about learning something about a conditional distribution $p(y\mid x)$ based on samples from both $x$ and $y$. A majority of algorithms we will talk about are supervised algorithms.
Deciding what algorithm to use is an art form. To see which algorithm is best for your given problem, you have to test it's accuracy on your data. If the accuracy is acceptable to you and/or your company, you can then use that algorithm to predict new data. The basic steps for supervised learning are:
In contrast, unsupervised learning is used to cluster populations into different groups. There is no target or outcome variable to predict/classify. You're trying to extract information in general out of your data, allowing you to approach problems with little or no idea about what your results should look like. We can derive structure from data where we don't necessarily know the effect of the variables. Whereas in supervised, we already know what our correct output should look like and are trying to find the parameters that cause our features to result in the corresponding output.
View it like this. You're a 5 year old at a zoo, trying to tell the difference between a herbivore and a carnivore. Throughout the day, your parents point at different animals telling you which animal is a herbivore and which animal is a carnivore. You start to notice patterns. You start noticing that the animals with sharper teeth, tend to be a carnivores. Your parents then go to the restroom and leave you by yourself (terrible parenting!). You see an animal that you haven't seen before. Based on the previous animals you've seen and the pointers your parents gave you, you predict that the animal is a herbivore. Your parents then come out of the restroom, you ask them if it is indeed a herbivore, and they give you the correct answer. If you are correct, your testing accuracy is 100%, else, it's 0%. You are the machine learning algorithm. The animals' teeth, legs, and demeanor are it's features. The animals you see throughout the day is your training set. Herbivore/Carnivore are your two label classes. You analyzing/learning each animal's features and your parents telling you which one is a meat-eater is the training step. That new animal you see is your testing set. Your parents leaving is testing the algorithm. If you were correct, you grow up to be a zoologist, which is analogous to the algorithm getting chosen to be implemented in the real world.
In the unsupervised case, you are an orphan. You have no parents to teach you. Better yet, you have no parents to even tell you what to look for. You have no idea what herbivore or carnivore means. You still go to the zoo and see animals. You see that some animals are more similar than others. You naturally group the animals with sharp teeth, and a hunter's mentality together. In contrast, you also group the animals with dull teeth, and a friendlier demeanor together. You do all this despite not knowing what herbivore or carnivore means. You have found structure without necessarily knowing what to look for. This is essentially what unsupervised learning is.
The third major way of learning is reinforcement learning where the algorithm performs a task and is either constantly punished or rewarded based on how it performed. This is exactly how you potty train a dog. More on all of these ways of learning later on.
There are also two major types of machine learning models: generative and discriminative models. Generative model tries to learn $p(y, x)$ while a Discriminative model tries to learn $p(y\mid x)$ directly during the training phase.
A generative algorithm models how the data was generated in order to classify. They generate data that resemble or are in some way related to the data they’re trained on. It builds a model of each class, and then compares a new piece of data to each model and predicts the most similar one. On the other hand, a discriminative algorithm does not care about how the data was generated, it simply categorizes a given output.
Another simple way to tell whether a model is generative or discriminative is to see if it involves calculating the distribution of $y$ or whether the model can generate a new set of training data if all parameters in the model are known. If the answer is yes, then the model is generative, otherwise it's discriminative. Naive Bayes is a generative algorithm because it can generate both feature data and label data easily. SVM is not because it cannot generate any data in the feature space.
Let's go back to you being a 5 year old at the zoo. You're being supervised by your parents and they're telling you which animal is which. When your parents tell you the animal is a herbivore, you meticulously write down several conditions like: if the animal is friendly and has dull teeth, it is a herbivore. If it has sharp teeth with a hunter-like vibe, it is a carnivore. With these rules, you detect which animal is which. This is discriminative.
Now, lets have the same setup, but instead of walking around yet, your parents give you two blank canvas, and ask you to draw what a meat-eater would look like, and what a vegetarian would look like. You draw two photos. Now, as you walk around, you compare what you see to your drawings. If the animal is more similar to your carnivore drawing, you predict carnivore, and versa-vice. This is generative.
This is a lot of theory. If this all isn't making sense to you yet, re-read and read on. It will all sink in eventually, especially when we discuss actual algorithms. Which is coming up next...