
$K$-Nearest Neighbors ($K$NN) is one of the easiest (but effective) algorithms in machine learning used for classification and regression. When I have a new piece of data that I want to classify, I simply take that new piece of data and compare it to every piece of data in my training set. I then store $K$ ($K$ can be set to any number) examples from the training set most similar to the new data point, and predict the majority label from those $K$ examples. The similarity metric is usually computed by the Euclidean distance. There is no need to train or create a model. All I need is data and to set $K$.
You’re a new student at a high school in Kansas. It's a stereotypical high school with a bunch of different cliques . It has the jocks, the nerds, the cheerleaders, the rock band kids, and the theatre students. None of these are mutually exclusive, but for this story lets assume they are :). You, being a new student wanting friends, look for the clique that's most similar to you to hang out with.
During your first week, you go around the whole school meeting each student (training data). You know what clique each student belongs to (label). When you meet each person, you compare your hobbies, wardrobe, and GPA (features). You record how similar they are to you in your journal, based off of those 3 features.
By the end of the week, you have met the entire school and decide it's time to fully integrate into one of the cliques. You look in your journal and decide that you are going to find the 5 (you set $K$ = 5) people that are most similar to you and are going to join the clique that the majority of the 5 belong to.
You see the top 5 people most similar to you are Ceejorn (jock), Nickenny (cheerleader), Nacolm (nerd), Dayaan (nerd), and Adam (nerd). You see that a majority of the people that are most similar to you are the nerds. You now classify yourself as a nerd. As a result, you hang out with the nerds for the remainder of your high school career.

$K$-Nearest Neighbors, unlike all the other algorithms, doesn't build a model. There is no training step. The main idea of it is to simply use the similarity between examples' features. The assumption that drives this algorithm is that similar examples should have the same label, which intuitively makes sense in real life. We also assume that all examples (instances) are points in $d$-dimensional space $\mathbb{R}^{d}$.
For example, if you wanted to classify whether someone was an adult or child (labels), and you were given 2 features (height and weight), you would model it with a 2 dimensional graph.
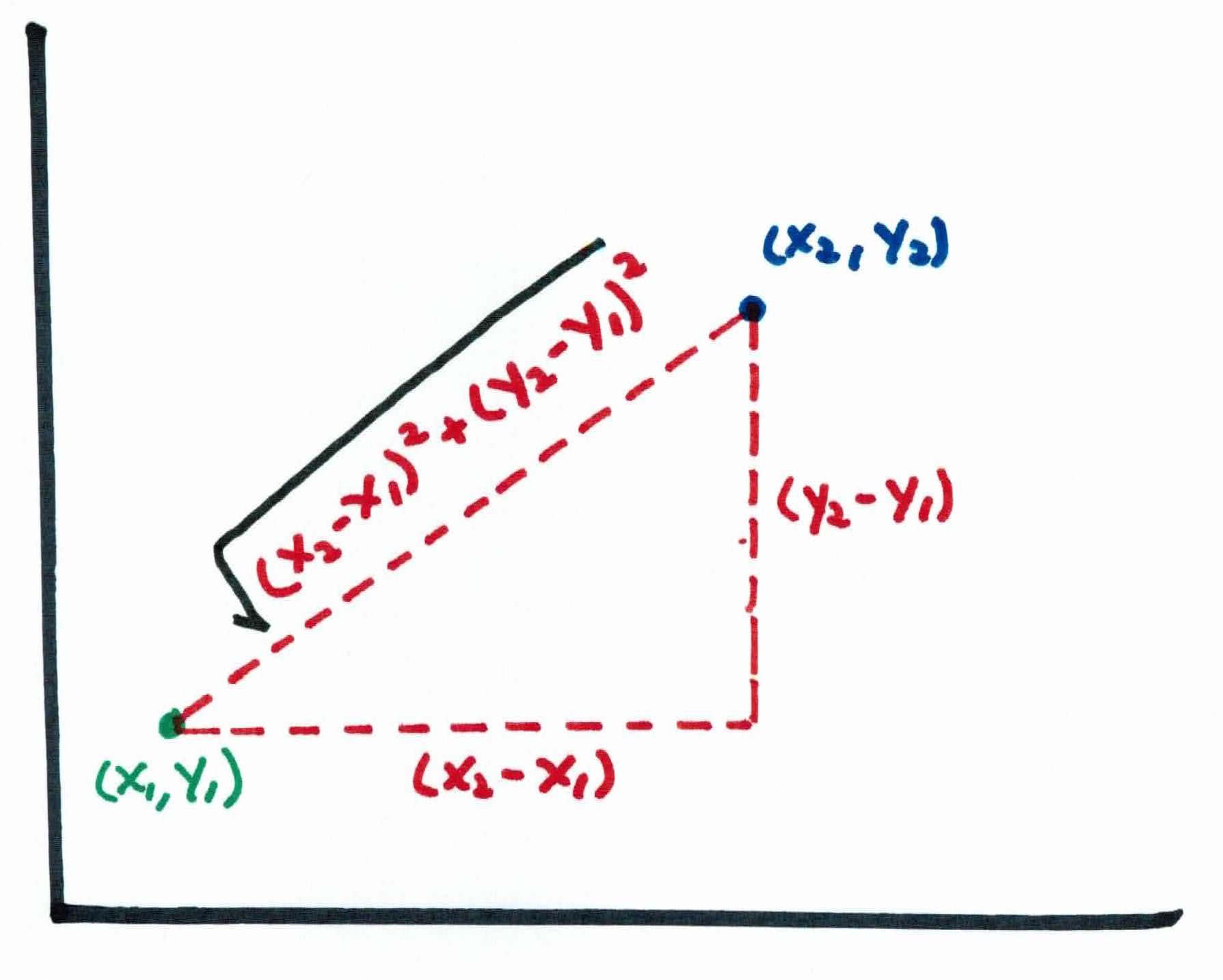
For our similarity measure, we use the Euclidean distance. The closer an example is, the more similar. Given two examples $x_i$ and $x_z$, we can calculate the Euclidean distance as:
$$d(x_i, x_z) = \sqrt{\sum^d_{j=1}(x_{i,j}-x_{z,j})^2}$$
with $j$ being each feature in the examples.
Given a new example $x_{new}$ that we want to classify, we simply compare it to our entire training set using the euclidean distance:
$$d(x_{new}, x_i) = \sqrt{\sum_{j=1}^d (x_{new,j}-x_{i,j})^2}$$
for all $i$ in our training set.
We then take the $K$ training examples' labels $y_i$ with the smallest euclidean distances, which correspond to the $K$ nearest neighbors, and place it in the set $N_K$, i.e. $N_2 = {y_3, y_{48}}$. Since all the labels are -1 or 1, we can simply compute:
$$y_{predicted} = sign(\sum_{x_i \in N_K(x_{new})}y_i)$$
which will return the majority label within $N_K$. That is the label we will predict.
If you're still a little confused, keep reading on and it should clear up by the time you read through the example section.
Given a training set ${(x_1, y_1), \ldots (x_n, y_n)}$ with $d$ features and parameter $K$, the $K$-Nearest Neighbors algorithm works like this:
Going with our example, assume we are trying to predict which clique you $(x_{you})$ will fit into the best.
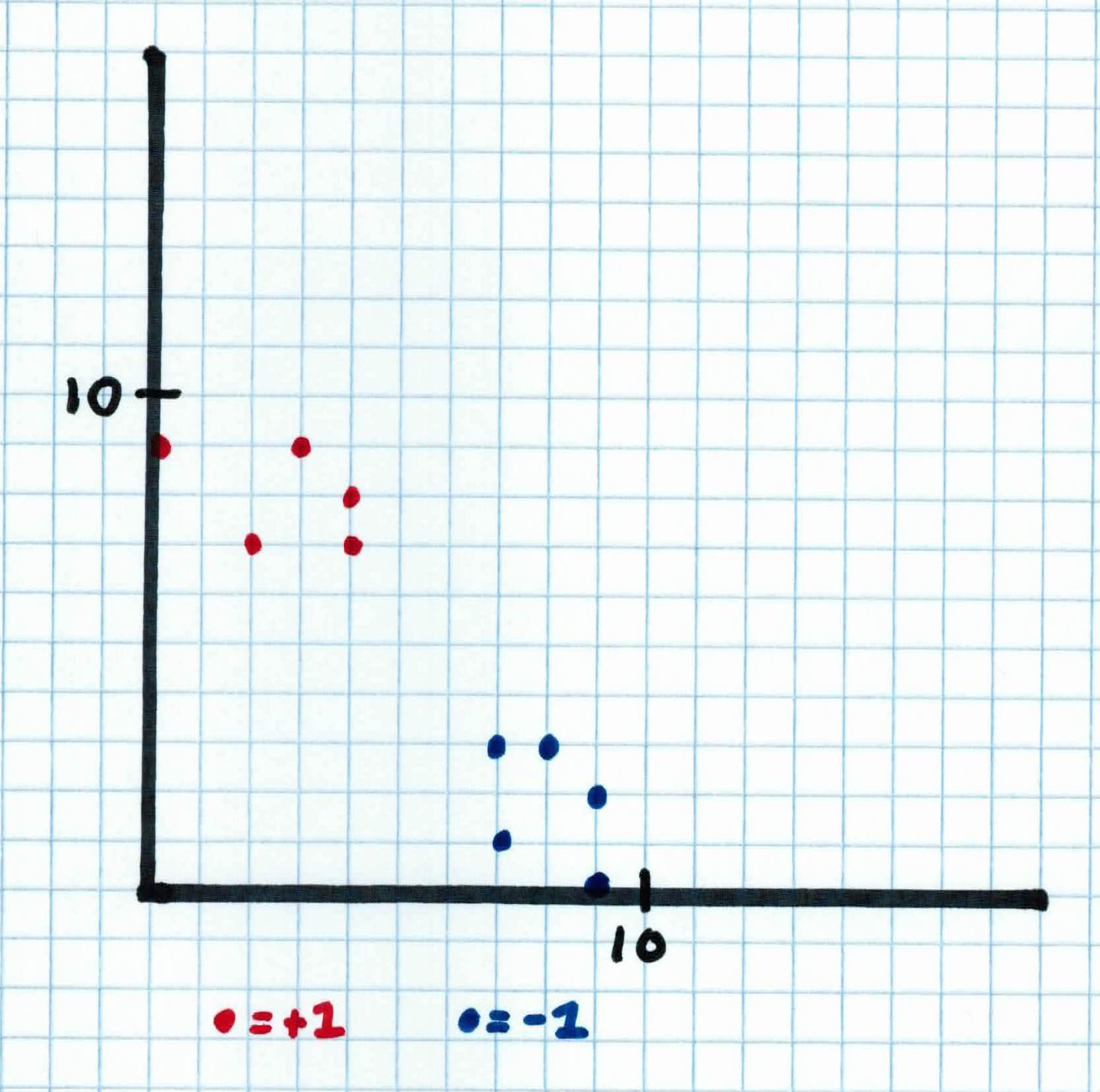
The two class labels are jocks $y =$-1 or rock band kids $y =$+1.
The 2 features are $x_{you, 1} =$ *love of sports* and $x_{you, 2} = $ love of rock music, all rated on a scale of 0-9. You love sports $x_{you,1} = 9$ and you're pretty neutral about rock music $x_{you,2} =5.$ So, $x_{you} = (9,5)$.
You are trying to predict which clique you will belong to $y_{predicted} = ?$.
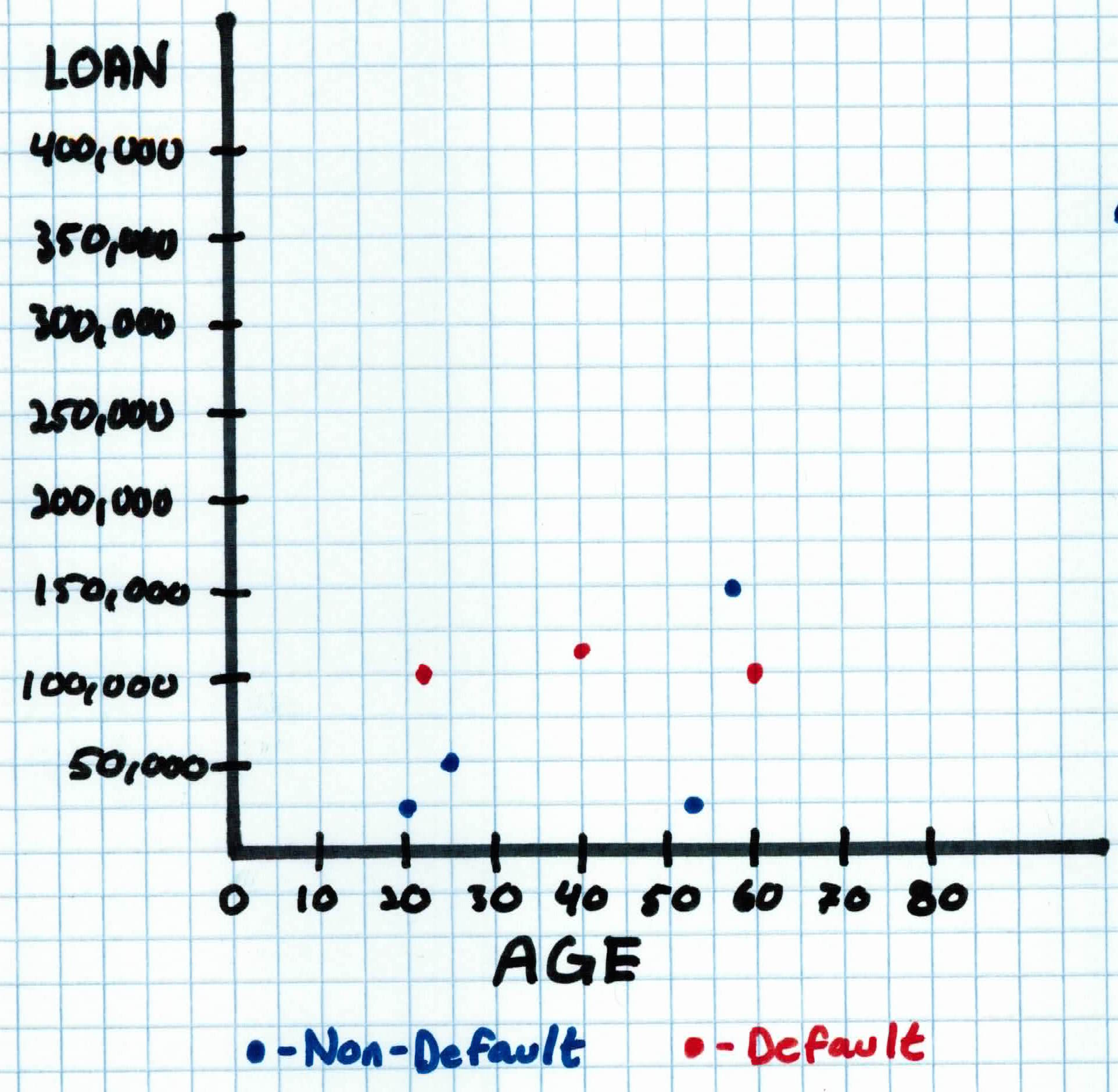
Let's say we set $K$ = 3 and we're given (training data) 10 students, 5 jocks and 5 rock band kids:
We compare each one's features to $x_{you}$'s features using the euclidean distance formula. For example, if we compare the 3rd person to you, we'd get:
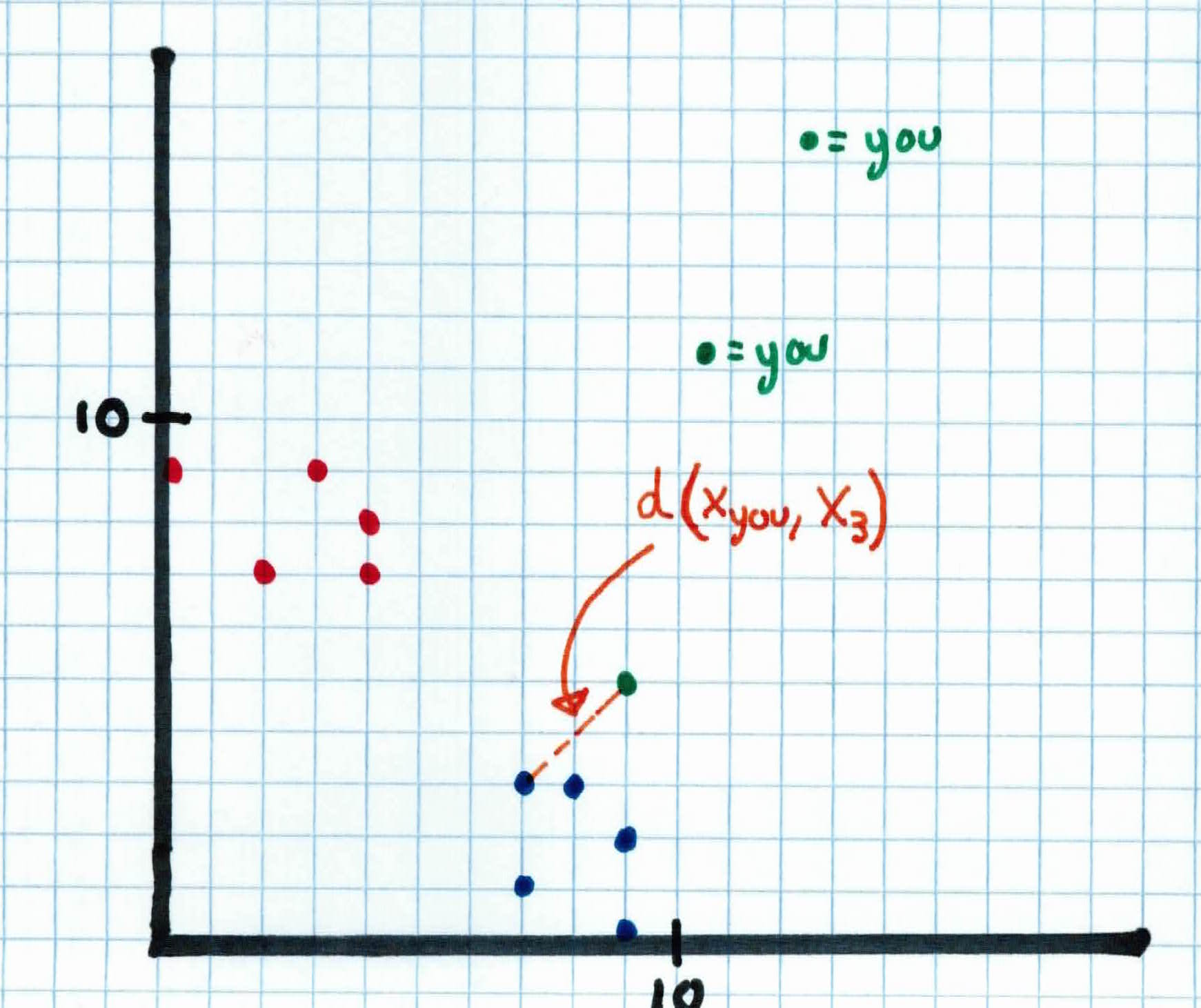
$$d(x_{you}, x_3) = \sqrt{\sum^d_{i=1}(x_{you,i}-x_{3,i})^2}$$
$$= \sqrt{(9-8)^2+(5-3)^2}$$
$$=1.73205080757$$
We calculate this for the other 9 examples and return the 3 smallest numbers in the set $N_K$ which corresponds to the 3 closest examples. The 3 closest to $x_{you}$ are $x_2, x_3, x_4$.
To find our predicted label $y_{predicted}$ we take the sum of the 3 labels corresponding to $N_K(x_{new}) = x_2, x_3, x_4$, given by:
$$y_{predicted}=sign(\sum_{x_i\in N_K(x_{new})}y_i)$$
$$=sign((-1)+(-1)+(-1))=-1.$$
So based off of your features, we predict that you will most likely get along with the jocks!
$K$-Nearest Neighbors is simple to implement, works well in practice, and can be extended easily with new examples. It does not require the user to build a model, make assumptions, or tune parameters.
There is no training step. When given a new data to classify, you simply compare that new data's features to each training example's features and return the $K$ closest examples determined by the euclidean distance. The predicted label will be the label of the majority of the $K$ examples.
In order to choose the most optimal parameter $K$, see cross validation.
Note that there are definitely cons when it comes to $K$NN. For one, it requires large space to store the entire training dataset. The actual algorithm can also be extremely slow! Given $n$ examples and $d$ features. The method takes $O(n\times d)$ to run. Last but not least, it could suffer from the curse of dimensionality if implemented by an approximate nearest neighbor search algorithm like a K-D tree, but is free if implemented using brute force.
Other observations: