
Ensemble methods is the art of combining diverse set of ‘weak’ classifiers together to create a strong classifier. They use multiple learning algorithms to obtain a better predictive performance than what could be obtained from any of the constituent learning algorithms alone. It means you build several different models then "fuse" the prediction of each model. The intuition is that the diversity of models can capture more aspects of the problem and gives better performance. We can create different models with only one set of training data by slightly adjusting the data for each model. We do that by using methods like boosting, or bagging.
You're Dan Gilbert, the owner of the Cleveland Cavaliers. Its your duty to build a championship team (strong classifier). In 2007, your team consisted of LeBron James and a bunch of below-average scrubs (<50%). Although you had one good model, the overall model was still inadequate.
Individually, LeBron James can bring a team to the Finals, but winning is a different story. But, if you add above average (>50%) players together, you have a chance. However, you can't just add any type of above average players together. You need diversity of models to capture any weaknesses. If you put all 3-point specialists on your team, then you run the risk of not getting enough rebounds. If you place too many big men on your team, you run the risk of not being to push the ball up the court. In algorithmic terms, you would be really good at classifying the same piece of data over and over again, but never the whole set of data.
You see that your team is struggling with pushing the ball up the floor, so you add more more priority (weight) to obtaining a point guard in the off season. The offseason comes, and you add Kyrie Irving, an above average point guard to push the ball up. You now lessen the priority (weight) of getting a point guard.
Now, your team lacks consistent rebounding, so your priority (weight) increases for finding a big man. After many iterations, you end up adding Kevin Love, an above average big man, and Kyle Korver, an above average 3-pt specialist.

When you combine these above-average players together, it increases the overall model and has a great chance in resulting into a championship team. This is how the ensemble method known as boosting works!
Recall that a randomly chosen hyperplane has an expected error of 0.5. So, if we were to combine many of these random hyperplanes by majority voting, the outcome would still be random.
However, supposed we have $m$ classifiers, performing slightly better than random, that is error = $0.5-\epsilon$. If we combined these $m$ slightly-better-than-random classifiers together, would majority vote be a good choice? The answer is yes, only if each of the classifiers are slightly-better-than-random on different parts of the data.
Why do ensemble methods work? Because we take the wisdom of the crowds. It's no different than the show Who Wants To be A Millionaire having a lifeline called Ask the Audience allowing the audience to vote for which answer they think is best. The show assumes that the majority of the people voting come from backgrounds and will collectively make the right choice.

Ensemble methods are learning algorithms that construct a set of classifiers and then classify new data points by taking a (weighted) vote of their predictions. They combine the predictions of many individual classifiers by majority voting. When combing multiple independent and diverse decisions each of which is at least more accurate than random guessing, random errors cancel each other out, and correct decisions are reinforced.
Such individual classifiers, called weak learners, are required to perform slightly better than random! Weak learners can be trees, perceptions, decision stumps, etc. But, how do we produce independent weak learners using the same training data? We use a strategy to obtain relatively independent weak learners by manipulating training data to make it learn multiple models. Different methods for changing training data include boosting (reweighing training data) and bagging (resampling training data).
Boosting, sometimes synonymous with Adaboost, is one of the more commonly used ensemble methods. Originally, it was developed to guarantee performance improvements on fitting training data for a weak learner that only needs to have training accuracy greater than 0.5. It was then revised to become an algorithm called Adaboost, which builds ensembles that empirically improves generalization performance. Examples are given weights, and at each iteration, a new hypothesis is learned and the examples are reweighed, placing more weights on examples that the new hypothesis got incorrect.
Given out training set, we learn $m$ different weighted versions of the data with $f_i$ for all $1 \leq i \leq m$!
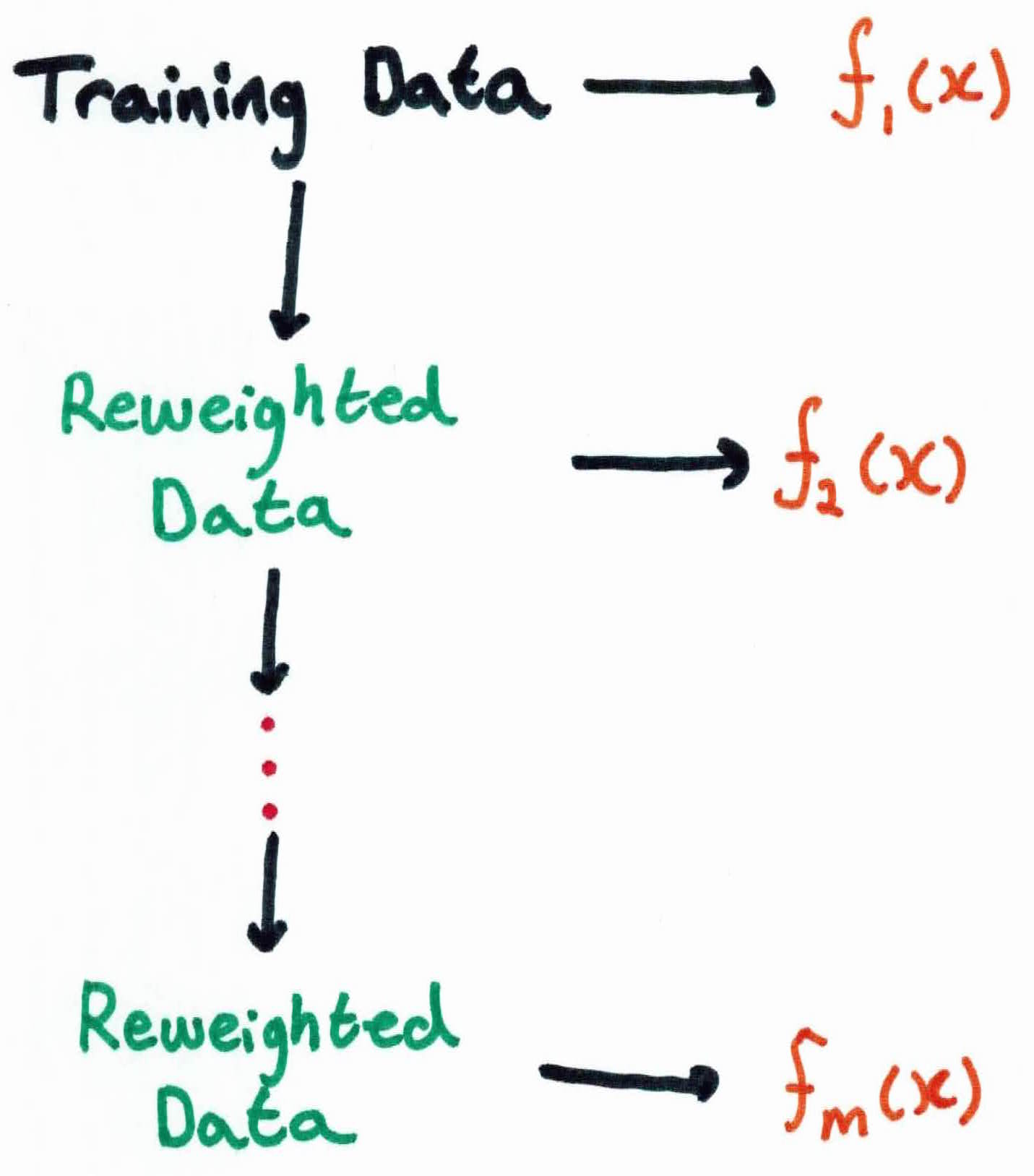
The predictions from all of the $f_m$, $m \in { 1, \dots, M }$ are combined with a majority voting to form the final classifier $F$:
$$F(x) = sign(\sum_{m = 1}^M \alpha_m f_m(x))$$
where $\alpha_m$ is the contribution of each weak learner $f_m$ computed by the boosting algorithm to give a weighted importance to the classifiers in the sequence. The decision of highly-performing weak classifiers in the sequence should weigh more than poor performing weak classifiers in the sequence. This is captured in:
$$\alpha_m(err_m) = \frac{1}{2}ln(\frac{1-err_m}{err_m})$$
where for each weak learner $m$, we associate an error $err_m$, given by:
$$err_m := \frac{\sum_{i=1}^n 1 { y_i \neq f_m(x_i)}}{\sum_{i=1}^n w_i}$$
The function $\alpha$ shows the importance of each weak classifier. So if the error is very small, then the $\alpha$ will be very high. The graph of the function looks like this:
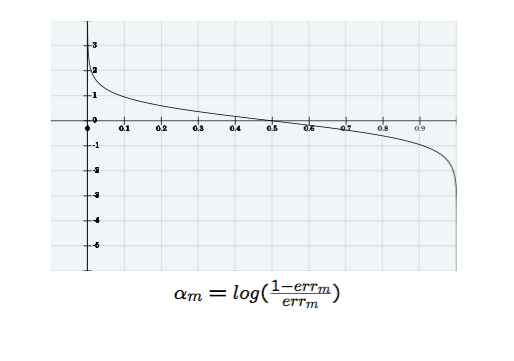
Recall that the error rate for the weak learners $f_i$ are divided by $w_i$ because the errors they are making are with respect to the weights. So, if the weak classifier makes a mistake on an important piece of data (high weight), the error will be higher than a mistake it made on a piece of data it's already classified correctly (low weight).
The error rate on the training sample with the final classifier is still:
$$err := \frac{\sum_{i=1}^n 1{y_i \neq f(x_i)}}{n}$$
Remember, we are adding different classifiers together to get one ultimate classifier. So, we obviously need to have different training data to create different classifiers, or we'd just be adding the same classifier, making the same mistakes together, i.e. team full of 3-pt specialists. So, we have to adjust each training example. Is there a way to present the same training set in a different way to each classifier? We can do that with weights. We'll give more weights to the examples that were misclassified after each iteration. So we update the weights like so:
$$w_i \leftarrow w_i * exp[-\alpha_m (y_i f_m(x_i))]$$
Make sure you truly understand how we're updating our weights. Plug in some synthetic numbers to see when it increases/decreases.
This adds weight to the examples that were classified correctly and lowers weights from the examples that were misclassified. This encourages the next weak learner to correctly classify the data that has previously been misclassified, because the weak learner will try to lower it's error rate.
For each of the classifiers $f_m$ we are getting an $\alpha_m$ that tells us how important is this classifier in the final answer of making this decision.
Bootstrapping is a re-sampling technique, based on sampling from an empirical distribution.
Bagging is an machine learning ensemble based on a bootstrapped sample that aims to improve quality of estimators. Bagging gets its name from Bootstrap aggregation. Bagging and boosting are based on bootstrapping as they both use resampling to generate weak learners for classification.
The strategy for bagging is simple. Randomly distort data by re-sampling and train each weak classifier on a re-sampled training set. It creates ensembles by repeatedly randomly resampling the training data. Given a training set of size $n$, create $B$ samples of size $n$ by drawing $n$ examples from the original data, with replacement.
Each bootstrap example will on average contain 63.2% of the unique training examples, the rest are replicates. We simply combine the $B$ resulting models using simple majority vote. Bagging works as such:
For $b = 1, \dots, B$
$$f_{avg} := \frac{1}{B} \sum_{b=1}^B f_b(x)$$
Given a training set ${(x_1, y_1), \ldots (x_n, y_n)}$, the Adaboost algorithm works like this:
Given training data ${(x_1, y_1), \ldots, (x_{10}, y_{10})}$, we will use Adaboost to learn from the data:
$$x_1 = (1,4), y_1 = 1$$
$$x_2 = (1.5,2), y_2 = 1$$
$$x_3 = (3.5, 5.5), y_3 = 1$$
$$x_4 = (4,6), y_4 = 1$$
$$x_5 = (5,5), y_5 = 1$$
$$x_6 = (2.5, 1), y_6 = -1$$
$$x_7 = (3, 4.5), y_7 = -1$$
$$x_8 = (4,4), y_8 = -1$$
$$x_9 = (6,2), y_9 = -1$$
$$x_{10} = (6, 5.5), y_{10} = -1$$
After plotting the data, we get:
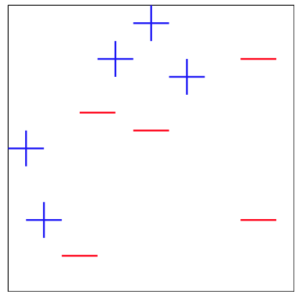
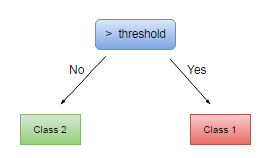
For our weak learner, we will use tree stumps. Tree stumps are simple binary rules that split data into two classes. They take in an input, compare it to the threshold, and return which class it's in (true or false), such as the rule $x \geq 3$. If your data's corresponding feature is $x=4$ then it will return True!
Initially, all weights will be initialized to $\frac{1}{n}$, so it ours will be $\frac{1}{10}$.
Our first classifier will be a decision stump with the rule $f_1(x_{i}) = x_{i,1} > 2$, because that is what minimizes our current error.
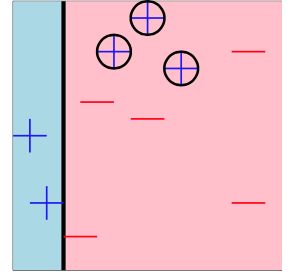
The data that are misclassified are circled and the error comes out to be $err_1 = \frac{3}{10}$.
We then calculate $\alpha$ which is the weight of our current weak classifier $f_1$. The lower the error, the higher the weight!
$$\alpha_m = \frac{1}{2}ln\frac{1-err_m}{err_m}$$
$$\alpha_1 = \frac{1}{2}ln \frac{1-\frac{3}{10}}{\frac{3}{10}} = .423$$
Next, we adjust each weight based on whether they were classified correctly or not. If an example is misclassified, we increase the weight on it so that the next weak learner puts more emphasis on getting it correct to minimize it's error.
So, for example, for $x_3$ the true label is $y_3 = 1$ but our current weak classifier predicted it as $f_1(x_3) = -1$. Since we have a misclassification, we will put more weight on it using the formula:
$$w_i \leftarrow w_i * exp[-\alpha_m (y_i f_m(x_i))]$$
$$w_3 = \frac{1}{10} e^{-.423(-1)(1)} = .152$$
For a correct example, say, $x_1$, we have:
$$w_1 = \frac{1}{10}exp^{-.152(1)(1)} = 0.0858$$
We do this process until all weights for correctly classified data has been reduced and weights for misclassified data has been increased. The next weak classifier will attempt to find a rule to minimize error and with the weight on incorrect examples increased, it will try its best to make sure those examples are classified correctly.
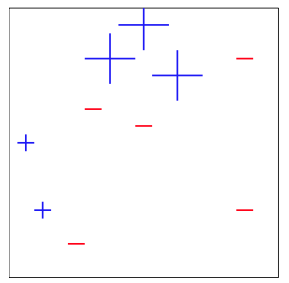
After updating all of the weights based on our current weak classifier $f_1$, we repeat the steps for the remaining $M-1$ classifiers. Each time, choosing a new classifier that will minimize the new weighted error.
After iterating through two more times, we get the following result:
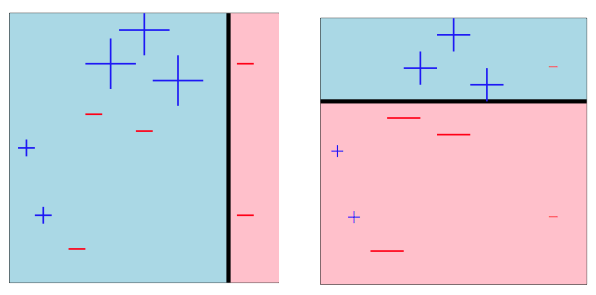
Our final classifier after combining $M$ weak classifiers will be:
$$F(x) = sign(\sum_{m=1}^3 \alpha_t f_m(x))$$
$$F(x) = sign(.42f_1(x) + .65f_2(x) + 0.92f_3(x))$$
The final classifier has now combined the merits of all weak classifiers, creating one super classifier, the same as the Cavaliers!
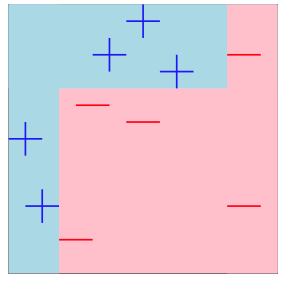
The goal of ensemble methods is to combine the predictions of several base estimators built with a given learning algorithm in order to improve generalizability/robustness over a single estimator. They are learning algorithms that construct a set of classifiers and then classify new data points by taking a weighted vote of their predictions. It's goal is to learn multiple alternative definitions of a concept using different training data or different learning algorithms.
The methods of ensemble we talked about were bagging and boosting. In bagging (bootstrap aggregation), the first step involves creating multiple models. These models are generated with random sub-samples of the dataset drawn randomly form the original dataset. Meaning if you want to create a sub-dataset with $m$ elements, you should select a random element from the original dataset $m$ times. There are some methods that use the bagging strategy differently, like random forests, which uses random feature selection.
Boosting is used to describe a family of algorithms which are able to convert weak models to strong models. The model is weak if the error rate is high but at least above $0.5$. Boosting incrementally builds an ensemble by training each model with the same dataset but the weights of instances are adjusted according the the error of the last predictions. The main idea is forcing the models to focus on the instances which are hard. Unlike bagging , boosting is a sequential method, and so you can not use parallel operations here.
Other observations: